It’s not beautiful
Python comes bundled with fantastic mocking support in its standard library. C has no such high level mocking support.
As was famously said by those folks at ISO who maintain the C standard:
The Committee is content to let C++ be the big and ambitious language.
The C standard is revised only once per decade, and any changes tend to reflect existing features the compilers already support.
Since there are no agreed upon mocking approaches to get into the current process, don’t expect any built in help until at least the 2030s.
There are however at least three obvious ways to do what is called “Interpositioning” and third-party high level mock libraries tend to be synaptic sugar around one or all of these techniques.
So googling for the more general term interpositioning rather than mocking tends to result in more useful search results, and a common example given is how to replace malloc with your own interpretation or wrapper of malloc. This is probably all you need to know and you can take it from here.
A lot of the examples call the compiler directly, so you end up doing cargo cult programming, trawling open source project code for the correct recipe to stick in your own Makefile.am
Other uses of interpositioning
Apart from mocking, it is worth saying that there are other (more specialised) reasons why you might like to intercept a call to a function,
Apart from reverse engineering something you don’t have the source for, the main reasons are adding encryption to things, sandboxing things and profiling things.
Like all monkey patch type approaches, if you do this with other people’s libraries, you have to track their development very strongly, and if you are doing that, you might as well submit your changes to upstream or at least ask that project for the relevant calls so you feature can be added without intercepting functions.
Of course, your interest in mocking is to write unit tests for your own libraries, so you don’t have this problem.
Types of interpositions
Back to the main topic, we interposition our replacement (i.e. mock) function at three places. One approach seems to be more popular than the other two.
The first less popular approach is to intercept the function at compile time i.e. when the source of the application code is compiled, your mock function goes into the application binary instead of the original function.
The second less popular approach is to intercept the function at runtime by your tests loading the application code as a dynamic library, this is known as “the LD_PRELOAD trick”.
Anything fed to the environment variable LD_PRELOAD in your makefile is used first.
Your mock functions are given precedence (pre-loaded) so when the application code tries to define that function, it is already there.
The last and most popular approach is to get the linker (ld) to do all the heavy lifting for you.
Giving the linker the argument –wrap and the name of the symbol(s) you want to wrap, changes how those symbols are resolved.
So in the malloc example, you call your own malloc function __wrap_malloc and then it is used instead of malloc.
The original standard library malloc is still available but gets renamed into __real_malloc.
The idea being that if your __wrap_malloc first wants to do something (like log some information or something) it can still afterwards call __real_malloc
–wrap symbol Use a wrapper function for symbol. Any undefined reference to symbol will be resolved to __wrap_symbol.
Any undefined reference to __real_symbol will be resolved to symbol.
So you just have to use the prefix __wrap_ for your wrapper function and __real_ when you want to call the real function. A simple example is:
Or just fake it
You may be able to avoid any of this by clever use of header files, i.e. make it so when the test runner is compiled, a different header file is used for those functions that you need to mock.
Putting “if we are in the test runner, use this header file” macros in the application code will horrify purists though so at least try to put as much junk as possible in the Makefile rather than the C code.
Firstly, at compile time
Compile time: When the source code is compiled Link time: When the relocatable object files are statically linked to form an executable object file Load/run time: When an executable object file is loaded into memory, dynamically linked, and then executed.
High level mock functions only work on x86 because they go under C and inject machine code.
Some other approaches involve running tests of your C code in a C++ compiler and using extra C++ features to do the job.
Premade C wraps from people associated with the samba project
https://packages.debian.org/buster/libuid-wrapper https://packages.debian.org/buster/libnss-wrapper https://packages.debian.org/buster/libsocket-wrapper https://packages.debian.org/buster/libpam-wrapper https://packages.debian.org/buster/libresolv-wrapper
LD_PRELOAD
You put all your mocks into one library.
First load MockLibrary Second Load Application code (and standard library and third party libraries etc) Third Load Test Runner (whose main is run).

The last time I did some unit testing on C, I used Novaprova. However, at least at the moment, this doesn’t run on non-Intel platforms (like the ARM based Pi).
I decided to make a quick survey of what tools there are. I focused mainly on the ones that are already available through Linux package managers.
Everyone loves Autotools
The leading approach seems to be to use autotools’ built-in test runner i.e. “make check”.
To choose two of my favourite projects at random, VLC and JSON-C, both follow this approach.
Using GCC’s built-in preprocessor and linker gets you some way to mocking and so on.
A lot of applications roll their own test runners using bash or Python scripts.
If you are using a big framework, you may have already installed testing utilities as part of it, for example GNOME’s Glib and Boost (which is C++) both come with their own testing tools.
Without further ado, onward to the tables. Currently, these are just in approximate alphabetical order.
C Only
| Name | Apt Package | Projects Using It |
|---|---|---|
| Check | check | Expat, GStreamer |
| cmocka | cmocka | libssh, OpenVPN |
| CUnit | libcunit1 | OpenDataPlane |
| GNU Autounit | libautounit-dev |
C and C++
| Name | Apt Package | Projects Using It |
|---|---|---|
| API Sanity Checker | api-sanity-checker | |
| CppUnit | libcppunit-dev | LibreOffice |
| CppUTest | cpputest | |
| Criterion | criterion-dev (ppa) | |
| CTest (CMake) | cmake | Netflix, ZeroMQ, libpng, Poppler |
| Cutter | cutter-testing-framework | libnfc, Groonga |
| DejaGnu | dejagnu | GCC, Other GNU tools |
| Google Test | googletest | Chromium, LLVM, OpenCV, Blender |
C++ Only
There are loads of C++ testing utilities such as Catch and CxxTest (and too many others to mention) that do not claim explicit support for C.
If you want to use one of those, you can just test your C code using a C++ compiler.
Some purists will object, as in this Stackoverflow comment:
I know C and C++ has a lot of overlap, but it doesn’t strike me as a good idea to use a C++ testing library when you’re producing code that will be ultimately compiled in a C compiler
Tell me your stories
I haven’t had the opportunity yet to go beyond listing them.
What are you using? What have I missed?
I’m especially keen to get more information to fill in the third column in the table above (i.e. what any testing tools vaguely well known open source projects use).

People talk about the UK becoming an independent country again. However, normally we have been on the other side of the table, the first time being when the United States of America left the British Empire.
As regular readers will know, I like to view history as a history of technology, and of course being over two centuries apart, American Independence and Brexit are using very different technologies.
The Treaty of Paris
The peace negotiations between Great Britain and the American revolutionaries (as well as other interested European powers) started in April 1782 and came to a text on November 30, 1782, it was signed by September 3rd 1978 and fully ratified by all parties by April 9th 1784.
This was an intercontinental treaty, completely handwritten paper based system using horse messengers and ships going back and forth between the US and Europe. Yet, in less than two years, they made world peace and setup the United States of America, including a comprehensive free trade agreement and mutual respect of each other’s laws and borders.
The Treaty of Brussels
The UK voted to leave the EU on 23 June 2016. Since then not much visible progress has been made in regaining control of the UK’s laws, money and borders.
After the vote, instead of immediately leaving the EU, leaving was pushed to Friday, 29 March 2019, almost three years later. It remains to be seen if this deadline will be met.
As an independence movement, it is not exactly motoring ahead.
Brexit has direct train service between London and Brussels (1 hour 51 mins), email, computers etc etc. We don’t even have to invent a new country, we just have to go back to pre-EU policies.
The speed comparison between American Independence and Brexit shows how ridiculously dysfunctional the EU is and how moribund and atrophied the British state has become.
In this case, technology is not getting a good reputation, all these great communication technologies are just prolonging the inevitable rather than moving us closer to the eventual resolution.
However, at least to get to Brexit’s beginning, we had a war of social media memes rather than a war using rifles.
We will get there in the end
The USA set a shining example to all the other colonies of the British empire and eventually the era of European global empires came to an end. When Brexit finally happens, the UK won’t be the last country to leave the EU.

Project Fear Fantasies (again)
On the leave side of the EU referendum campaign, it was always clear that no peaceful and law-abiding EU citizen living and working in the UK was going to be sent home. Absolutely no one on the Leave side advocated it. It is a dead parrot.
The Remain campaign however was busy fighting their own straw men instead of what the Leave side was advocating, which is one reason why they lost. People could see their parrots were dead.
One of the Remain campaign’s apocalyptic fantasies was that Brexit would lead to a mass deportation of EU nationals and so the public services and private sector businesses would collapse having lost millions of nurses and other workers in one day.
We are all the heathens

The Great Heathen Army after being defeated by Alfred the Great were not put back into their Viking longboats, it was not practical, and they are still here. They became a big part of what we now call Northerners.
The Irish Republic began over a century ago, yet still not a single right has been removed. Any Irish citizen living here in the UK has always had a pretty full set of rights which have nothing to do with the EU. The British people are generous, they do not hold grudges against Irish people or Danes.
Rather more recently, it cost tens of millions to remove Two (2) Islamist hate preachers. Not two thousand, two hundred, just two.
Without any national register of citizens or identity cards, the fact that the British state has absolutely no way to even know who is here, let alone have any means to do any mass deportations.
3 guys claiming to be 3 million guys
I thought this nonsense died with the remain campaign but no it is still going. I came across a pressure group self named the3million [sic], quite a presumptuous name. Not a scientific sample by any means but the EU citizens that I ran across in my daily life had never heard of it.
It is also quite an assumption that all of the EU citizens in the UK share the same set of views. Not least because in most EU countries, support for the EU barely gets to 50%, and in many cases is much lower.
The idea that the 3 million EU citizens have the same views on Brexit is as preposterous as imagining they all wake up and sing Ode to Joy every morning.
EU citizens are not uniform
As I listen to British resident EU-citizens about Brexit, they have very different opinions, often related to why they chose to come to the UK in the first place. I am putting them into three groups.
The UK joined the EU 18 years late in 1973 and was so unenthusiastic that it had its first leaving referendum in 1975. The UK has had a Eurosceptic Majority since they started recording these things in 1992 (and perhaps all along). The UK refused to join many of the main EU programs like the Euro, the Schengen Area and countless others.
However, according to the3million campaign there are apparently people that somehow moved to the UK without knowing any of this or somehow being in denial or in a complete information-free bubble.
Therefore the first group I am calling the Shocked and appalled group. They feel they came to the UK under a certain set of conditions (EU membership) and the goal posts have been moved. However, not seriously enough they want to actually move back to the EU.
It suits the establishment not to make these people at ease, to have a victim class that they can wind up like clockwork mice and point in the right direction when necessary. These are the tearful ones used in BBC vox pops and those holding up signs on the3million website.
The second group is your unpretentious honest hard-working Economic migrant - they don’t care about the long-run politics of it as they are just here temporarily for the money until they can build their own mansion in the Eastern European countryside. (Though sometimes they go native and end up in the third group below).
They are chilled (or even happy) about Brexit because (a) they already got in the door and (b) any controls on future migrants means they can increase the cost of their manual/practical skills that native British workers are not likely to acquire any time soon due to the lack of technical educational in this country.
The final group is the Gone-native group. They came because they were Libertarian-minded and liked British culture. They can do a fairly decent John Cleese impression. They were expecting Brexit to come sooner or later and as long as they don’t fill have to fill out too many forms (because they have gone native and now like most British people, they hate forms), are generally chilled. They would have applied for citizenship but cannot be arsed, because it is another load of endless forms.
What we don’t see is a massive wave of EU migrants emigrating out of the UK. Applications for National Insurance numbers by EU immigrants are still at record rates and still rising. This is not North Korea, people can leave at any time. However, they are voting with their feet to stay.

However much moaning might happen on Facebook, they have chosen with their homes and pocketbooks, to stay on the good ship Britannia and go with us on our new global journey.
So it is only right that our Prime Minister has made a very generous offer that EU citizens living and working here can receive the same benefits as the British population under the same law.
What is not acceptable is using the status of EU nationals as a means to keep the UK in the EU by the back door. That is not what people voted for.

The EU’s position paper called Essential Principles on Citizens’ Rights demands, among other things, that:
The Commission should have full powers for the monitoring and the Court of Justice of the European Union should have full jurisdiction corresponding to the duration of the protection of citizen’s rights in the Withdrawal agreement.
If the ECJ can be an mediator in every interaction the UK government or a company has with an EU citizen, then we will still have no ability to fix any of the pressing issues facing this country, including the still unresolved causes of the 2008 crash. Every government policy has winners and losers. Every bad policy has some corner-case where someone benefits from it.
With 3 million or more EU citizens, any issue can be turned into an issue affecting an EU citizen providing forum shopping and then the EU law will apply.
The idea of everyone being equal before the common law and that UK judges are trusted to apply it is anathema to the EU’s Napoleonic position that only the ECJ can be trusted to protect EU citizens.
This is really a “special interest”/“closed shop” self serving argument, if national courts can be trusted, there is no point to the EU. To protect its own need to exist, the EU has to insert itself into everything, even if it is not needed.
The US Supreme Court doesn’t need to interfere if an American citizen resident in the UK has a problem with a public institution or company, that American just uses the normal UK courts to plead their case.
The UK has residents who hail from the whole world including millions of citizens from the other 169 countries in the world that are not in the EU. They manage quite fine to use the existing UK Courts. They don’t need their legal systems to intervene in British law.
Note there is no reciprocal right in the proposal for British citizens living in the EU to call for assistance from the British courts.
This whole lop-sided proposal shows how the Euro-federalists see the UK as a difficult colony, not as an independent country or let alone as an equal partner.
Staying under the law of the EU is not Brexit, we would have just moved from a colony with very little say of how we are governed to a colony with no say over how we are governed.
It is not the independent country that people voted for.
]]>
For those reading later, Facebook was an early 21st Century “Social Network”, it was web application that you can sign up to and share text and pictures with other users.
1. Tangent on why I don’t use Facebook

I was at University when Facebook started so I got an early invite when it was a University based system. I quit in 2006 when it became available to the whole public and stopped being connected to the physical campus. I am not some kind of elitist, it just lost any meaning to me at that point. I am surprised it is still going a whole decade later.
There are no real barriers to talk any of my old school friends, many have parents still living in the same place as my parents and moving in the same circles as my parents but for whatever reason we didn’t bother keeping up.
Suddenly, I was being collected by such people in the race to get more ‘friends’ and was being distracted with requests to play scrabble and vote on things and so on.
Many normal people seem to have taken on this horrific American practice of presenting a horribly bland PR-style over-positive view of yourself. Everyone on Facebook is Hyacinth Bucket from Keeping Up Appearances.
Unless, like Pheidippides, you brought important news about how you have defeated the Persians and then died on the finish line, I don’t really care about the marathons you are training for.
Unless you are sending me a slice, I don’t care about the cake you made. Unless you have wired it up as an IoT project, I really don’t care about your cat.
2. From the Web to the Mesh

For those in the military and Universities, we made our own networks. To provide internet to homes and businesses, commercial ISPs moved in.
This however was not the only possible model. Before BT was privatised, it had its own plan to provide a national data network to be run by the post office.
Since then, hundreds of municipal wireless networks have been setup. Wikipedia maintains a big list.
Rather more interestingly, there are many attempts to get away from the centralised, corporate/government controlled Internet altogether.
Remove the ISPs, the DNS, etc and just depend on distributed Mesh Networks where every node has everything required to fully connect to the other nodes. This is a mathematically superior approach which in the end will require a lot less electricity, bureaucracy and cost.
However, when all nodes are equal, there is not any obvious point where organisations like the CIA or GCHQ can stick themselves as a man in the middle, and there is little ability for the government to censor or cut anyone off using easy digital means.
But it is fine. It is too expensive to make water pipes care if you use the water for drinking, cleaning your car or for water boarding a terrorist suspect.
It is not economic to replace the roads with special surfaces that turn to mud if a bank robber is performing a getaway.
3. I still miss Gopher

In 1991, the leading Internet content protocol was Gopher. It had automatic client-side formatting and strong typing of content files, removing many security problems that WWW faced.
It was also easy for anyone to add to gopherspace, you didn’t need coding or graphic skills.
However, WWW was completely public domain so won, despite its technological shortcomings. By 2017, we have lots of tools like markdown, bootstrap, Jekyll/Sphinx etc which mean you don’t have to put a lot of work into making a readable website.
This blog is statically generated using Sphinx and there is no serverside code. I am paying absolutely nothing for you to read this.
It is getting easier all the time, but it is still not as easy as it should be to add your own content to WWW.
5. Jesus Vs Pontius Pilate

Pontius Pilate served as governor of Judaea then retired to his villa in Rome. Did he even remember executing Jesus? To him it would have seemed like one of many local disputes he dealt with. Being a colonial overlord was known to be a hard gig.
Pilate got a lot of bad PR, being the baddy of the Easter story but that was later. Pilate was most probably already dead long before Christianity spread far enough for Rome to notice it.
Jesus got tortured and executed then got a billion followers and a seat at the right hand of God, but no villa.
Jesus had two friends named James, his brother and James, son of Zebedee. One was thrown off the temple and/or stoned to death, the other had his head cut off with a sword (Acts 12:1-2). James does have a cathedral built over where his head was buried but he didn’t get a villa either.
It is one thing to get millions or billion of followers, it is another thing to keep your head on your shoulders as well.
6. The silent majority

I never really felt like being a Jesus figure. Most people don’t, I talked a lot about the silent majority before.
The loudest people in tech are from the West Coast of the USA. Meanwhile, software developers and professors working within Universities can go native and be as left wing as the other professors.
However, the vast majority of developers are like the majority of most other people, just in the centre.
The crazy far-left minority are just disproportionately loud. When they bring their politics into a space or event not to do with politics, people mostly just politely humour them and nod along while looking at their watches or checking their phones.
No one breaks their bubble, people are keen not to prolong it any further. They have organised childcare or transport and want to just get on with fly-fishing or software development or whatever got them to the event.
Those far-lefties without self awareness may take this to mean everyone agrees, however this is a mistake, they are unprepared for events like Brexit or Trump when the majority show they don’t really care that much about their sacred cows.
Once all the centrist and the conservative speakers have been purged from Facebook, the silent majority will just silently fade out as their timeline gets boring and other things get invented that are more interesting than pictures of cats.
VR, IoT, the Mesh’s first killer app, whatever. There is always something new.
7. Technology is progress

A lot of the crazy left today is anti-technological. It is mathematics that will save the world not socialism or “Intersectionality”.
The famous book by Kernighan and Ritchie (K&R) has done more to progress humanity than Marx’s Communist Manifesto.
As I expressed in parts 14 and 15 of my previous essay: politics, as expressed in parliament, is really not that important. It is just dealing with the effects of technological change.
The character of Viktor Komarovsky in the famous Boris Pasternak novel Doctor Zhivago is a businessman or fixer who works with and benefits from the aristocracy. When Communism takes over, he carries on in the same role just with new clients.
Over the Twentieth Century, politics and culture have lurched back and forth from free market capitalism to socialism to this current corporatism and now we may be going back to capitalism.
However, software has just pressed on. From Turing through to K&R to Linus Torvalds and so on, we are in a line. Moore’s law, the compiler, the web, robotics, AI, the singularity. No one can stop us.

2016 led to a clear divide between the Deplorables and the Hysterics. Where did this come from? What is the historical context of Brexit? What should we in the UK make of President Trump? What role did technology play in making this division?
This is another long read typed at the speed of thought, as always, corrections and improvements are appreciated.
1. Where to begin

In my first essay on Brexit, Rome Vs The Matrix, I started at the last Ice Age and went through each of the attempts to include Britain in a United Europe project. This post will be somewhat more modern.
The 1975 referendum was a Labour affair, the pro-EU yes campaign led by Harold Wilson and the No campaign led by the great Tony Benn.

In 1975, Benn and the leavers were accused of wanting to turn the UK into an island of socialist utopia, it is not so relevant to this current hysteria.
Therefore, I will start my story at 1992, for in retrospect, this is where the Leave campaign began its march to successfully winning a referendum on leaving the EU in 2016.
1. Maastricht Rebels - the battle of the bastards

One of the reasons that Prime Minister Margaret Thatcher’s long and electorally successful leadership was challenged by her own party was her resistance to further European integration.
Under her more successor, John Mayor, the 1992 Maastricht Treaty was negotiated. This converted the European Community to the European Union, including European Economic and Monetary Union (the Euro being finally set up on in 1 January 1999), but also lots of other areas of policy being handed over to the European level.
This was not popular in the British parliament. Ratification was not easy or quick and took another 18 months. A vote on one wrecking amendment was tied 317-317 and only defeated because of the 1876 convention of the speaker breaking ties by voting no.
Prime Minister John Major famously called three members of his cabinet (Michael Howard, Peter Lilley and Michael Portillo), the “bastards” - which was a still a controversial insult back in 1993.
Meanwhile, while this Tory civil war was happening in Parliament, over at the Bank of England and the Treasury, there was a different European problem.
The inability to find an interest rate that would fit both Germany and the UK led to a run on the pound and consequently the UK being ejected from the European Exchange Rate Mechanism on Black Wednesday, further pushing the UK away from Europe.
The combination of Black Wednesday, the way Thatcher was deposed and the way Prime Minister John Major ruthlessly pushed the Maastricht Treaty through parliament, splintered his party and the wider conservative movement, and now in retrospect, sowed the inevitable seeds of Brexit.
The elite MPs in control of the party machine had become de-anchored from the mass of the Conservative party membership and the general public. This led to a landslide defeat at the 1997 election and 13 years out of power.
However, those anti-EU forces created in the Maastricht ratification process continued in the background.
Some of the leading 1992 rebels are still in parliament, for example, Sir Bill Cash. While some of the younger ones, such as Dr Liam Fox and Iain Duncan Smith, became the backbone of the Leave campaign.
Outside of the Tories, UKIP was began in response to the Maastricht Treaty, it came into being between 1991 and 1993. On the day John Major signed the Maastricht Treaty, an up and coming 27 year -old conservative called Nigel Farage quit the Tories and became UKIP’s first nationally recognised leader.
2. The great Euro non-debate

By 1996, Britain’s place in Europe was not clear, with the Tory members and much of the public wanting less Europe, while the pro-EU John Major and big business wanting the UK to join the Euro in time for its launch in 1999.
For ten years between 1995-ish to 2005-ish, there were two competing campaigns on the Euro.
There was the campaign, financed by big business, for Britain to join the Euro, with prophesies of doom and irrelevance if the UK didn’t join.
This culminated in the group Britain in Europe led by Tony Blair (in theory but unwilling to expend political capital on it), Gordon Brown (in theory but in practice going the other way, as we shall see below) as well Ken Clarke, Michael Heseltine, Charles Kennedy and so on.
Meanwhile, on the other side, the was No Campaign primarily backed by Sir Tim Rice of musical theatre fame and supported by all the “bastards” from part 1 above.
All this preparation by the two campaigns happened in a kind of political-geek parallel universe, it never bothered the general public. Eventually, the money ran out and the two campaigns faded out before they really started but it was a practice run for 2016 when many of the same characters and same old arguments would re-emerge.
3. Things can only get better

In the 1997 election, Labour outflanked the pro-EU John Major by pushing the Euro question into the long grass, with the famous five Economic Tests, reportedly invented by Ed Balls in the back of a New York taxi.
A work of electoral genius, Labour now had defused its own European divisions with this technocratic measure. Those against further integration could see the tests were not currently met and could hold faith that convergence would never happen, while those in favour of further integration could hold faith that convergence would naturally occur and the tests would one day be met.
As it turned out, the UK and Eurozone economies diverged and the prospect of the UK joining the Euro stopped becoming a realistic option to anyone but the most extreme Euro-federalists, a rare breed in the UK.
The UK entered the 2008 financial crisis with more dodgy banks and a bigger national deficit than most of the Eurozone, including Southern Europe.
However, the UK having an independent currency acted as an automatic stabiliser and the UK made it through the crisis relatively unscathed in the short term.
Meanwhile, those in Southern Europe, lumbered with an unsuitably strong currency, suffered immeasurably more, proving the UK had dodged a bullet. The economic situation of Greece is what the alternative future of the UK could have been had we adopted the Euro currency.
4. Big business credibility problem

The abortive pro-Euro campaign was led by big business such as the City of London banks, Lord Sainsbury and so on, as well as the international institutions and think tanks. The exact same people and organisations that came back in the Remain Campaign of 2016. Not entirely, some like James Dyson and JCB had moved to the Leave campaign.
A lot of the “project fear”-type arguments had been made in the late 1990s and early 2000s about staying out of the Euro. However, the reality of the financial crisis had proved them all wrong, not entering the Euro had saved the UK.
The credibility problem of the UK pro-European campaigners was pretty clear to anyone with eyes to see in the outcome of the UK financial crisis.
Those against the EU since 1992 had been largely winning on democratic and legal grounds but losing the economic argument. However, in the aftermath of the financial crisis, the economic argument for the EU as an economic magic bullet was becoming increasingly untenable as the UK economy recovered steadily while the populations of many Eurozone countries were being collectively punished with mass unemployment in order to keep their economies within the Euro.
This is the background to the later Michael Gove style argument, why trust these people and groups when they always get their predictions wrong?
5. Lisbon Loons

The 2010 Conservative manifesto was called “Invitation to join the government of Britain” (PDF) and on pages 113 to 114 (pdf page number 124-125), promised a referendum before handing over any more powers to Europe.
However, when it came to the Lisbon Treaty, David Cameron weaseled out and said the promise would apply to every treaty after the Lisbon Treaty.
The Lisbon treaty was a massive step forward in the federalisation of Europe and the last major treaty likely to be approved for a long time, so Cameron’s promise turned out to be worthless (like all his other promises).
Some Tory MPs tried to honour the promise anyway, here we quote a 2013 Guardian Article:
The senior Tory made the remarks - in earshot of journalists - after being asked about the decision of 116 Tory MPs to defy the prime minister and vote in favour of an amendment regretting the absence of a EU referendum in the Queen’s speech.
The Conservative said: “It’s fine. There’s really no problem. The MPs just have to do it because the associations tell them to, and the associations are all mad, swivel-eyed loons.”
Major called his rebel MP bastards, the Cameron set now considered the largely Eurosceptic rank and file to be “mad, swivel-eyed loons”. Cameron had the coalition with the Liberal Democrats to average out the Eurosceptism of the Tory membership.
6. Cameron in a corner

Cameron entered the 2015 election with a promise to renegotiate its relationship with Europe and put that to an in/out referendum - page 72 (PDF page 74) of the 2015 manifesto (PDF).
How this was supposed to work in David’s Cameron’s mind probably involved the context of a coalition with the Lib Dems.
In the months before the 2015 election, the media has factored in an Ed Miliband victory or at least the unpopular David Cameron would be scrabbling around for a coalition with the Lib Dems who might be smaller but still significant.
Instead, the Tories won an outright majority, not least because the referendum pledge re-united the grassroots behind the government rather than UKIP. Cameron came back into power in 2015 with a party more Eurosceptic than ever.
The most pro-EU party, the Lib Dems went from 57 seats to 8 seats, i.e. an 86% loss.
While many MPs were loyal to David Cameron in the referendum, they were answerable to extremely Euro-sceptic local parties, and constituencies that were increasingly Eurosceptic too.
In the manifesto, David Cameron had promised to hold the referendum by the end of 2017, however pretty much the day after the 7th May 2015 election, Britain’s place in the EU became the hot topic to the exclusion of everything else.
Almost a year later, in April 2016, I remember thinking then that pretty much every argument that could be made, had been made. Luckily, David Cameron set the date of the vote to the 23rd June.
On the 24th of June, I was like phew, finally we can talk about something else but Britain leaving Europe, but no, the losing side didn’t disarm but carried on campaigning. We still are drowning in this one issue. Anyway I am getting ahead of myself.
Why did Cameron hold the vote earlier than needed? Did he believe it the European issue was preventing progress on any other issue? Did he believe he had it in the bag? Did he want a successful remain vote to be his legacy act before leaving the stage?
Perhaps his hand was forced by Merkel and Hollande, not wanting the UK relationship to become an issue in the 2017 French and German elections (well they failed there).
7. The campaign

I have talked a lot about the campaign and why leave won and the mistakes made by remain. Remain didn’t put their best arguments first. Remain didn’t update their arguments to take account of the 2008 financial crisis and the situation in Greece.
The Leave campaign had seen all the remain arguments coming from 15 years before and were ready for them.
I have covered the economic side in other posts and why Brexit didn’t cause an immediate recession as promised by the project fear (which had lost all credibility in the previous iteration 4 - The Gove argument).
I could talk about a lot of things but want to focus one thing, namely what those who wanted to leave were called by the remain campaigners.
Like “bastards” and “mad, swivel-eyed loons”, the elite hysterically called the people names. I went back to the 9th June 2015 edition of Question Time (link will expire 12th June 2017) and made a list, in this single program, leavers were called:
- Economically illiterate
- Manics that want to burn the economy
- Little Englanders
- Uneducated
- Trying to cause third world war in Europe.
- Liars
- Nazis
- Removing hope from the world
- Causing the breakup of the United Kingdom
- Want to cause a civil war in Northern Ireland
This was just one episode of one program, we had months of it. Later in the campaign it escalated to:
- Old people should not be allowed to vote
- Leavers are all racists that caused the Murderer of Jo Cox and a wave of crime
My favourite was when President of the European Council Donald Tusk said:
I fear that Brexit could be the beginning of the destruction of not only the EU but also of western political civilisation in its entirety.
If the remain campaigners were confident in their economic case, there would not have needed to be this demonising of the leavers. It was an act of desperation, a slow communal mental breakdown of the ruling class, the delayed unwinding of the pre-2008 globalist consensus.
8. The people are not bothered

Despite all that constant fear mongering and rhetoric by the elite, 52% of the UK voters bravely decided to leave anyway. According to the pollsters Yougov and ICM, many more have joined the cause since the vote.
The institutions and elites and dire apocalyptic warnings have become like crying wolf, they have lost any credibility whatsoever, and just makes those who make them distrusted.
The people have become shame-proof, moan proof. But they remember who calls them names.
I think it is pretty hard to shame anyone into anything, it is not how you win anything. You win by building the biggest coalition. Remain could have possibly built a massive coalition but it didn’t want to, it preferred to call people names, especially the working class and the old.
9. In a galaxy far far away

Meanwhile on the other side of the pond something else was stirring. In 2011, Republican Senator John McCain called the Republican grassroots “Tea Party Hobbits“
In 2016, Hillary Clinton in her election campaign said:
You know, to just be grossly generalistic, you could put half of Trump’s supporters into what I call the basket of deplorables. Right? The racist, sexist, homophobic, xenophobic, Islamaphobic - you name it. And unfortunately there are people like that. And he has lifted them up.
Donald Trump had over 65 million votes. Any person with common sense knows there is not over 30 million racists and sexists running around.
The situation is not 100% the same as the UK but it is comparable in that it again demonising the population. I always thought Trump would win the Republican primary but this speech was the moment that I knew Hillary would lose.
10. Who is the heck is Trump anyway?

The same people calling leavers names, the people with the repeated credibility problems are now telling us that “Trump is literally Hitler”.
The 52% had to become thick skinned already and are suspicious of the elite media and institutions.
I was already slightly immune to this. For almost every US election in my lifetime, the winning President has been called evil or invalid by the losing side. It is all very hysterical until silly season ends and life moves on to some issue of the day.
Reagan was called a second rate actor and conman, until he lead the fight against the Soviet Union and was considered a hero.
Bill Clinton was derided as a socialist who was going to bring back the USSR yet many agree Clinton managed the economy far better than many of his predecessors and successors and kept America safe. It was the end of a golden age which his two successors largely bungled and threw away.
Piers Morgan said that Trump cannot be worse than George W. Bush who lied about weapons of mass destruction to get us into a poorly planned War in Iraq which led to a million civilian deaths and thousands of American, British and other soldiers being killed and even more being maimed.
I have a lot of sympathy for that statement.
Obama was derided as a Kenyan Muslim communist who would introduce death panels to wipe out old people. It is all just hysteria every time.
The greatest American president in history is FDR who saved the world from “literally Hitler” i.e. the actual Hitler.
Based on the limited amount of time that Trump has been in office, perhaps he is somewhere between the extremes of W. Bush and FDR ... as in no-one knows. Presidents rarely are remembered for how they started or what they campaigned for; events happen and the narrative always changes after the fact. Ask me in the year 2047 if Trump was good or bad.
11. Sex is not our business

When President Clinton, a 50 year-old married man, had relations with a naïve and impressionable 22 year-old White House intern, he was criticised domestically.
The UK has quite strong laws and policies on the abuse of a position of trust so a UK politician doing exactly the same thing today would not survive but given the Jimmy Savile revelations who knows what they could get away with back then.
However, in general in the UK, we don’t care about our politicians’ sex lives. This is a good thing.
Most people would find it hard to pick many of our Prime Minister’s spouses or children out in a crowd. We generally leave the spouses and children out of the public limelight. We have the Royal Family for all that.
Andrea Leadsom ended the referendum campaign as one of the winners, a woman on the up, she was in the running to succeed David Cameron as Prime Minister. When she was perceived, perhaps unfairly, to be playing the motherhood card, the media threw it back in her face in the most extreme way and her leadership bid came to a shuddering halt.
The position of the UK government on the Lewinsky scandal was that it was none of our business. When asked about this Blair said the words of Ruth (1:16):
“whither thou goest, I will go; and where thou lodgest, I will lodge: thy people shall be my people, and thy God my God”
Blair was always over the top but here he was correct. The transatlantic alliance between the US and UK is not about the personality of the current leaders, it is a permanent alliance between two peoples with the same language and many of the same values: common law, freedom, the enlightenment, strong defence against our enemies, democracy, rule of law and so on.
What is good for the Democrats is good for the Republicans, let’s not worry what President Trump said to a friend on a bus in 2005. I really don’t want to go down the route of making political capital out of our politicians’ private lives.
As Jesus (may have) said, let him who is without sin cast the first stone.
12. We are not doing a merger

The US and the UK have many differences, often determined by our histories and geography.
America feared the Royal Navy would lead a surprise attack on the US and topple the government, so militias were part of the national defence.
The UK doesn’t have a second amendment because we obviously don’t fear the British invading, we never had a tradition of mass gun ownership. When the British Bill of Rights talked about a right to bear arms it meant pikes. Our traditional solution to national defence was to fill the sea around us with ships and cannons.
During the existential struggle that was World War II, most of the UK population worked in the military or for the state directly or indirectly, everyone became used to getting healthcare and wanted to keep it after the war.
Churchill opposed healthcare free at the point of use in 1945 and the population kicked him out as Prime Minister, when he changed his mind, the voters gave him his job back.
So in the UK, there is a seven decade national consensus behind free at the point of use healthcare.
In the US, you get what you earn. It is the American way. The successful and hard working get the best healthcare in the world and the unlucky, the unsuccessful or lazy get pretty basic care or nothing.
In the UK, it is full on socialised medicine and it is a mean average - everyone gets the same - rich or poor. We do have waiting lists, we do ration. In a crunch, the system does put the needs of children and working age people above the old.
New expensive treatments may not be initially available like in the US. The NHS might sit on its hands and wait for the producer to reduce the price or for a cheaper treatment to come available. Doctors won’t do meaningless tests for the sake of making money. People that are not sick or have minor things that can be self-treated, are told not to bother wasting a doctor’s time.
The minority of rich people who don’t like it, generally move to America and buy healthcare there. However, generally it works. The user has almost no paperwork to fill out.
While we do have waiting lists, you get on with your normal life, when you get to the appointed time, it is generally quite businesslike and there is not a lot of waiting inside the hospital, except when it all goes wrong because of staff shortages or planning foul ups, etc.
Gun control and healthcare and many other issues are domestic policies. We do not need the UK and the US to be the same.
Some people in the UK criticise the wall and Trump’s policies on border control. The UK is surrounded by rough, cold and unforgiving seas on all sides, it is a little bit hypocritical for the UK to criticise. In any case, it is for their own voters to decide.
13. Allies not clones

The important issue is how can the UK and US work together better to our mutual benefit? I agree with our Prime Minister Theresa May. It doesn’t matter if we in the UK love or hate many of Trump’s policies, we can still work together. We should try to work with everyone. Engagement is the British approach.
The UK has a powerful Navy, it is even more powerful when it works with the US military. We all need to take out ISIS and other terrorist groups.
We have complimentary economies, we can trade together. Trump has criticised Mexico and China for taking American jobs. The UK is not Mexico or China. Currencies are always changing but in January, the figures were:
US minimum wage: $7.25 per hour
UK minimum wage: $9.31 per hour
So the minimum wage is higher in the UK than the US, we can trade together for great mutual benefit with no risk of a race to the bottom.
14. The Hysteria is somewhat external

I am still asking for someone to tell me why President Trump is uniquely more hysteria-inducing than his predecessors. Most criticisms, valid or not, apply to a previous President or other.
It seems to me, the biggest difference between now and when President Bush came into office in 2002, and especially between now and when Reagan came into office in 1980, is the technological difference.
It was through better use of technology that allowed Donald Trump to leapfrog the big corporate media companies and beat 16 other candidates and the Democrats.
However, the same is true on the other side, that there is an echo chamber provided by social media and the World Wide Web which seems to magnify the hysteria.
Meanwhile email and the web give the ability to organise an event or protest far more cheaply and efficiently than in the past.
15. Technology is always more important

2016 was a big year in politics but it is important to remember that politics is merely a response to cultural change which is driven by technological change. Politics is dealing with the symptoms. Technology is the underlying cause.
The invention of the printing press allowed an information revolution which led to the Renaissance, the Enlightenment and the Industrial Revolution. The consequences continued for hundreds of years.
When Sir Tim Berners-Lee created the World Wide Web, it was the final piece that allowed a new information revolution to begin. President Donald Trump and those opposing him are political results of this revolution but they will not be the last. This thing will run for hundreds of years.
As Sir Winston Churchill said, “Now this is not the end. It is not even the beginning of the end. But it is, perhaps, the end of the beginning.”

I have never met a Leave voter who wanted to stay inside the Single Market or Customs Union. Quite the opposite. It seems pretty clear to me that leave the European Union means leave it.
The people were the jury
In order to secure re-election, the government offered an EU in-out referendum in their May 2015 election manifesto.
Prime Minister David Cameron tried to do a last-ditch compromise with the EU but it refused to offer any meaningful concessions.
In the 13 months between election and referendum, those who wanted to remain or leave the EU made their arguments in a campaign that (to me) seemed to go on forever.
The whole point of a vote is that it was up to the British public to decide who to believe, to act as a jury to judge whose arguments were right and whose were wrong.
In a historic turnout, 17.4 million people voted to leave the EU, more than have ever voted for anything before.
After the 13 months of the focus being on Brexit, I thought the vote would decide it and the focus of the nation would move on to other topics. No such luck.
Cadaveric spasms
Several politicians and prominent establishment figures on the remain side of the argument have never accepted the result and have been replaying the already too-long campaign all over again.
These establishment figures didn’t learn the most important lesson from the campaign, that the population are not fools and are not scared of doom scenarios.
Whenever such a figure says “I respect the result but” and then gives a ‘project fear’ argument already previously rejected in the vote, it shows they don’t actually respect the result.
After an initial attempt to get a re-run of the vote failed to gain traction, they have moved on to try to re-define what leaving the EU means so that Brexit becomes leaving the EU in name only. It is a sleight of hand trick.
They started with ‘leaving the EU does not mean leaving the single market’ but then News shows and Youtubers compiled clips of all the major figures on both sides before the vote saying leaving the EU would mean leaving the single market.
Now they are focusing on the ‘Staying in the Customs Union’ as if this was some separate project. It is not, the Customs Union is the core of the whole EU. If we stay in the Customs Union, we lose the biggest advantage of Brexit, and for me personally, half of the point of doing it at all.
That advantage is having Free Trade deals with the growing part of the world. I talked more about this several times including in my last post.
In the following table I list 10 Countries that have publicly approached the UK for a trade deal post-Brexit vote. There may be more but these ten will prove the point.
| Country | % world GDP | Population (million) |
|---|---|---|
| Australia | 1.67 | 24.3 |
| Canada | 2.04 | 36.3 |
| China | 15.1 | 1,382 |
| India | 2.99 | 1,326 |
| New Zealand | 0.238 | 4.6 |
| Norway | 0.5 | 5.3 |
| South Korea | 1.87 | 50.1 |
| Turkey | 0.978 | 80.0 |
| Gulf CC* | 1.824 | 53.8 |
| USA | 24.7 | 324.1 |
| Total | 51.91 | 3285.5 |
While declining in importance, the remaining 27 countries of the EU form an important market:
| Country | % world GDP | Population (million) |
|---|---|---|
| EU 27 | 18.432 | 435 |
The GDP of these 10 countries that seek a trade deal with the UK have a combined GDP three times larger than the EU 27 and a population 8 times larger. Almost all of these countries have higher GDP growth than the EU.
Maintaining access to the single market is important, but many times less important than gaining improved access to these 10 global markets. The disparity gets wider every day and every year as the developing world increases both its GDP and its population.
To join the EU, we had to throw away free trade deals that we already had with many of these countries, so being stuck inside the Customs Union has made us much poorer than we could have been, and staying inside it in the future will certainly restrict the UK’s potential economic growth.
Leaving Twice
The raw economic numbers are clear, it is better to have a clean Brexit and offer the EU a bi-lateral free trade deal. It is also nicer to our European neighbours in the long run.
If the government goes with some compromised (‘soft’) form of Brexit that stops the UK making free trade deals, including the power to remove tariffs and agree common standards etc, then there will just be a second round of Brexit.
The campaign to leave the EU really began in 1992, it took 24 years to get enough momentum to win a referendum. The second round will not take so long, we are mobilised and engaged already.
The UK already annoyed our partners by being in the EU but being unhappy tenants - we demanded a (partial) rebate and we refused to join many of the recent programs such as the Euro, Schengen, etc.
We then voted to leave. If the government signs a deal with the EU in 2019 that includes staying within the Customs Union, but then five or ten years later, the people vote to leave that too, we are throwing away any remaining goodwill we have left.
So it much nicer to our European neighbours to leave once, rather than mess them around by partially leaving and then leaving properly.
- Gulf Cooperation Council - Bahrain, Kuwait, Oman, Qatar, Saudi Arabia, and the United Arab Emirates
Follow the money
Those upset about Brexit like to see it as an isolated mistake that came from nowhere.
This is not a random event. Most events are never isolated, and Brexit is no different. It is a symptom of a wider trend.
Our exports to the EU have been falling since 2000 and especially since the financial crash of 2008.
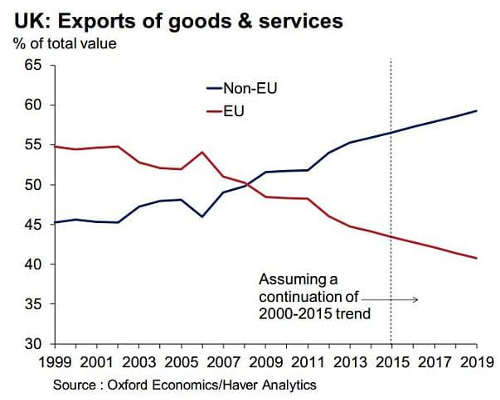
Meanwhile our trade with the 84% of people that are not in the EU has been growing.
You don’t have to be an economic genius to work out why this has been happening, the developing world has been booming, while the EU keeps choosing job destroying policies and then when those jobs are gone, uses the decline as an excuse to double down on nonsense and kill some more jobs.
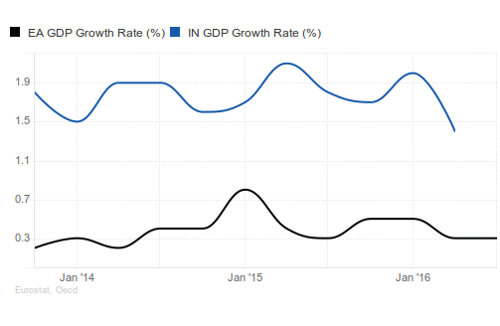
To pick a country almost at random, lets compare the Euro area to India. The quarterly GDP growth of India is five times higher than the Eurozone.
This is not a recent trend. Lets look at the ten year graph:
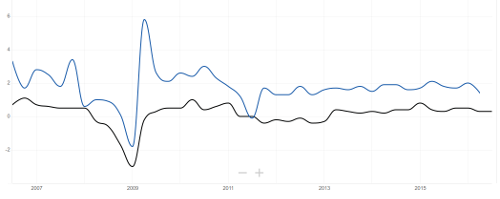
India’s growth is always higher than the Eurozone, look at 2011, India can have a battle with Pakistan, risking Nuclear annihilation, and still not go below the Euroarea’s growth.
This is not just a ten year trend, India has beaten European growth my whole lifetime. It is repeated across the developing world. The Eurozone has mostly flat or negative growth, while the developing world keeps doubling its GDP to very surely catches up to our level of wealth.
What these graphs show is that for the UK to maximise its wealth, we have to get out there and be a global trading nation once again.
The 2008 crash showed that the square mile of the city of London cannot pay for 65 million people. Since then we have just been running our country on fumes, currency manipulation and denial. We are going to have to use the whole of the UK and actually make and do things again that people want to pay for.
There is a lot of spare supply side capacity in the Midlands and North, and a lot of the human expertise is still there, grey and soon to leave the workforce but available right now. Luckily, we are waking up just in time.
The remoaners are going to moan for a generation
I ended my post The End of the World is Cancelled saying that Britain and Europe will get beyond Brexit and the relationship will be better than ever.
We won’t have such luck with our domestic malcontents however. The long-term inevitable and unavoidable trends above are totally ignored by Europhiles. It is a zero-sum game where the growing 84% of the world not in the EU don’t exist.
There are a lot of reasons for the professional remoaner class. Here are a few of the most obvious ones:
- People are used to patronage from the EU. However, this was always our money to start with, we can calm the nerves Universities and Museums etc by stuffing their mouths full of gold. There is so much waste and duplication in the EU that we can double the grants of everyone and still be in profit.
- EU salaries are often unbelievably good with endless handy perks. So Brexit has cut off the easy career path for a lot of the establishment who were expecting to upgrade to the European level: judges, politicians, civil servants, policy wonks, etc.
- EU elections happen between UK government elections, so for MPs, it is handy backup option to become an MEP if you are unexpectedly get kicked out by the voters. European elections are based on a list system so it doesn’t matter how personally unpopular you have become. Likewise minsters and high level civil servants can become commissioners and so on.
- Due to the above reduction in insider jobs, the private sector revolving door has never been more powerful. The finance industry has a lot of spare cash (time for more taxes?) and it hasn’t demobilised from the Referendum campaign. MPs like Nick Clegg who seem unlikely to keep their seat at the next election, are gearing up for the next job. Just look how much cash he is already taking from the banks.
I could go on and on, but if you have read my post The Treaty of Losers, you know I just cannot ignore the Occam’s Razor question that is bugging me. Maybe it is nothing to do with these reasons listed above, maybe it is much simpler and more obvious.
Occam’s racists
Until now, because the UK has been controlled by the EU, it could never agree to anything with its Commonwealth allies, the Commonwealth turned into a bit of a talking shop. However, it is turning back into an important body now.

As I talked about in previous posts, citizens of the Commonwealth countries volunteered in their millions to fight and die for us in World War II. Why wouldn’t everyone want to re-establish links with these great countries?
Looking back at the first part of this post, we have everything to gain. Who wouldn’t want to do trade deals with the massively growing commonwealth economies?
The answer is the remainer politicians and the establishment experts, who won’t even dare to discuss it. They bang on about having access to a (declining) market of “500 million people” (which includes UK so it is actually 435 million) but they never talk about the 2.3 billion people in Commonwealth or the 6.5 billion in the non-EU rest of the world.
Is this because it will just undermine their argument or is there something simpler going on?
Look back at the Commonwealth Heads of State, now look at the EU leaders:

Do you spot the difference?

In my previous posts, I talked about the importance of us as a country getting involved in the Commonwealth countries. Luckily we have an opening. The Commonwealth countries are still there and they want to work with us, with a bit of humility, the former masters can become the servants. There is a lot of goods, services and expertise we can provide to help the continued development of their countries.
My main point throughout my Brexit posts is that I do not believe that having a bilateral trade arrangement with EU rather than being a member is Armageddon.
Indeed, when we are finally free of the stifling customs union, we can really target improved relations with the rest of the world. Especially the Commonwealth which is now 2.3 billion people and most of world growth, as well as the United States and anyone else who wants to come with us in global free but fair trade.
We have all the cards

There is a lot of bluster from the EU, but that is for domestic consumption and deflect from the fact that national leaders in the EU Council of Ministers thought it could ignore British’s demands for reforms and the British people wouldn’t call its bluff. It did and now we have to move on. There is no going back.
On almost every issue, the EU needs UK more than UK needs the EU.
A nation of shopkeepers

European nations and companies rely on finance from the city of London and they sell to us a lot more than we sell to them.
If the EU does not give tariff free access to the EU, the UK will retaliate in kind. The EU has already lost a lot of jobs due to putting sanctions on Russia, many areas of Europe will be equally badly hit if this happens.
Meanwhile, we have a free floating currency, we can win any tariff war by devaluing the pound. The Bank of England can buy back government debt through quantitative easing. Our exports become cheaper, removing the effect of the EU’s tariff, the government has less debt and domestic production becomes more competitive. Triple win.
Meanwhile, outside the customs union, we can substitute almost any EU product with far cheaper global imports. South African or Australian wine might not initially have the same brand power as French wine but it still gets you drunk, and fashion is not a one way street, they can also move to meet the circumstances.
A nation of ships

UK is the main military power of Europe. European leaders know if they anger the British public so much that defending EU countries becomes politically impossible, then how will it defend itself from Putin’s next adventure?
Meanwhile The EU does not have the money to create an equivalent force and it takes a long time to make the martial culture required to be effective. In Afghanistan, the German troops refused to leave base without British guards. Putin’s men have no such scruples.
A nation of immigrants

Ignoring the Irish people who are unaffected by Brexit due to pre-existing and ancient rights, there are three million great and mostly young people working in Britain from other EU countries. It is going up not down since Brexit. Due to the relative economic strength of the UK.
Those from Eastern Europe send remittances back to their families which is spent in local shops, this is quite important to the economy of many Eastern Europe countries.
Whereas the largest proportion of the one million British people in Europe are retired people in the Sun. On the whole, these seniors don’t need working rights, they don’t take the jobs, they just shop, eat and drink, providing essential extra income into otherwise quite fragile seaside areas.
We can offer whatever terms we want or don’t want. It doesn’t matter, the EU will have to accept them.
The EU deals with both trade and immigration so with Brexit it is all mixed up, however normally immigration shouldn’t actually have that much to do with a trade deal.
We haven’t sent people back to Europe since we beat the viking horde, we won’t start again now. We never had much immigration control against Europeans, I doubt anyone will notice that much of a difference after Brexit. Whatever tests we set (getting to that in a just a second), most people who want to come here will pass them.
The UK government always makes a meaningless immigration target, but that is not important. If we engage more with the 84% of the world that we have been mostly ignoring, then the booming economy will need more labour.
What people want is control. Post-Brexit immigration system needs to have the following features:
- Vet and interview people coming from terrorist hotspots so we don’t take in any more terrorists. Throw out existing known terrorists.
- Pick the best and brightest people we can find from the whole world.
- Treat everyone equally, i.e. don’t discriminate based on race, more on that in a future post.
Once immigration has a defensible system, it will stop being a political football and people will stop worrying about it.
It will all be fine

Since we joined the EU, we outsourced most of the important decisions to Brussels but the employee count of Whitehall and the rest of the British government did not get smaller, it just kept increasing. So over 30 years this increasingly pointless, bloated and atrophied class of bureaucrats is used to being told what to do.
Now these bureaucrats are panicking because finally they have to take some responsibility and do some work. Like an unused muscle it is providing resistance and some of it might be dead weight.
If I was a government department I would be showing how useful I am to the process of creating new UK systems. Obstructions might find themselves being worked around and replaced.
Assuming the government can provide leadership and overcome this addiction to sloth, Brexit is going to be fine.
It is interesting how the government created a new department for Brexit and a new department for International Trade. A new broom can clean best.
A full Brexit will finally lance the boil of frustration over Europe and allow us all to get on with things. As I said before in my post “Good fences make good neighbours”, Britain will go from being an unhappy tenant of the EU to Europe’s most supportive neighbour and ally.
We will get a workable free trade deal. The rest of Europe will get over it, indeed Britain never joined the Euro, Schengen, Fiscal Compact and dozens of other things, so in a decade, people in Europe will have forgotten that the UK was ever a member.
No such luck with our own domestic moaners, they will go on for a generation. More on that later.
Part of our failed membership of the European Union involved being in the ‘outer countries’.
Whenever a European Union politician wanted to dismiss the UK’s input from a decision, it would always bring up that it is not one of the “Inner Six” who are the ones who should have the final say. What is common about the Inner Six is that they were either all Axis countries or surrendered at the first major German offensive. They are really the “Inner Losers” of World War II.
| Country | Date of Surrender to Axis |
|---|---|
| Germany | Axis |
| Italy | Axis |
| Luxembourg | 10 May 1940 |
| Netherlands | 14 May 1940 |
| Belgium | 28 May 1940 |
| France | 22 June 1940 |
These are the countries that wrote the Treaty of Rome.
Here are the signatures:

And here they are, the signatories, signing the above treaty. Look how diverse are the signatories and the observers.

Who are these identical clone-like guys that get to represent their countries, are they some kind of war heroes? Sadly not, with a couple of exceptions, they managed to quietly shirk out of World War II despite being of fighting age. The war barely interrupted their wining and dining.
| Signatory | Role in World War II |
|---|---|
| Paul-Henri Spaak | Fled to London |
| Jean-Charles Snoy et d’Oppuers | Labour Volunteer in Belgium |
| Konrad Adenauer | In hiding (in his friends’ mansions) |
| Walter Hallstein | Nazi officer (artillery), got captured by Allies, Prisoner of War |
| Christian Pineau | French Resistance, got captured in 1943, rest of war in prison camp |
| Maurice Faure | Professor, joins resistance in 1944 (after Allies already winning) |
| Antonio Segni | Local government politician in Sardinia |
| Gaetano Martino | University lecturer |
| Joseph Bech | Fled to London |
| Lambert Schaus | Town Councillor, arrested in 1941, built motorways for rest of war |
| Joseph Luns | Got a post at the Dutch embassy in London |
| Johannes Linthorst Homan | Chairman of the Dutch Olympic Committee |
In this signing ceremony, they are meeting on the Capitoline Hill, the very centre of the Roman Empire. This symbolism is not to be ignored. They specifically chose to wrap this new Union in the symbolism of the previous attempts to unite the peoples of Europe ( see Rome Vs the Matrix for a lot more on this topic).
This treaty of signed by War dodgers of the Axis countries that just lost World War II, yet in their head they Roman emperors.
Union of Europeans
The EU traces its origin to this Treaty of Rome, the first line is:
DETERMINED to lay the foundations of an ever-closer union among the peoples of Europe,
On that same first page, we have a resolution “to eliminate the barriers which divide Europe” and to ensure “harmonious development” by “reducing the differences existing between the various regions”. It goes on in much the same way for 80 pages.
The implication of it all is that Europeans are a single people accidentally separated by borders and they should fix it with an ever closer union.
In my post Rome Vs the Matrix, I talked about how from Roman times until today, they have been trying to reunite Continental Europe.
The most immediate pre-brexit example is of course Hitler’s attempt to unify Europe in a Nazi Empire which I talked about in the post Godwin part two.
In short, the all white master race lost to the multi-racial armies of the Allies.
Both the Nazi empire and the EU follow an atheistic secular scientific approach, with religion and Christian culture pushed deep out of public life.
Most importantly they both use Roman era symbolism for their ends. The EU is a Union of White majority countries, with a customs union of external tariffs seeking to partially insulate the European economies from the rest of the world.
If you are from Bulgaria or Finland, you have freedom of movement to work and live into the UK, but if you are from Kenya or India, you do not. The former countries are white European countries, the latter are not. I am not the only one who spotted this.
Mein Kampf is written by a deranged socialist artist who became a dictator. The treaty of Rome is written by lawyers. However, they both have this concept of a United European people, both times they have a white majority, how convenient.
The deep pool of racism that led the Axis populations to condone Hitler didn’t magically disappear when the allied soldiers rolled in.
This concept of a unified European people is the middle-class educated lawyer’s version of a master race. Once you understand this, all the white supremacist euphemisms used knowingly and unknowingly by Europhiles become clear.
For myself, I don’t believe in this concept of a special united European people. I think someone from South Africa or Pakistan is equal to someone from Finland or Slovakia. We should work with everyone and not put up barriers to the 84% of humanity that are not in the EU, we should be equally open to everyone.

I had meant to write a sequel to my 2007 post on Godwin’s law. Over, ten years later, here I am.
The book Mein Kampf is the demented ravings of Hitler. It comes in two parts. The first volume is an autobiography and the second is his manifesto of National Socialism and his plan for a “new order”, which later he had an opportunity to try out.
Hitler’s philosophy was socialist in that he aimed to abolish individualism. He believed this process should begin from birth, and children should be educated in a system of total control, that minimises parental influence in favour of the ideas of the Nazi state.
The book also spends time explaining Hitler’s atheism, and his desire to remove Christianity from all public society. Obviously I don’t need to explain his views toward Jews. Hitler believed in pre-Christian neo-pagan style beliefs with his famous vegetarianism. He believed the pre-Christian Roman Era under Julius Caesar and Emperor Augustus was the high point of humanity.
Hitler believed in allying with certain Christian groups if it suited his strive for power, at least until after he had created his empire then he could totally abolish it.
For Hitler, Christianity is a Jewish plot to keep Europeans from understanding their true ancient “Aryan identity”, their natural superiority from being white and more highly evolved. Everyone else, including Slavic peoples, were Untermensch, subhumans.
Albert Speer, quoted Hitler in his book Inside the Third Reich:
“You see, it’s been our misfortune to have the wrong religion. Why didn’t we have the religion of the Japanese, who regard sacrifice for the fatherland as the highest good? The Mohammedan religion too would have been much more compatible to us than Christianity. Why did it have to be Christianity with its meekness and flabbiness?”
Instead of a heavenly Kingdom, Hitler believed it was his destiny to create a united Europe with himself at the centre. A new Roman Empire, with himself as Emperor. An Empire without meat, smoking or alcohol.
When George Orwell reviewed the book for a magazine, he called Hilter’s vision of a united Europe: “a horrible brainless empire”.
His atheistic secular scientific approach did mean he spent an enormous sum on Universities and research and development. Which is why at the end of World War 2, the allies raced with each other to grab all the Nazi scientists.
However, Nazi Germany couldn’t get many of their innovations into production in time to help prevent the total loss to the Allies. As it turned out, this master race of white Europeans wasn’t as good as it thought it was.
As I talked about in the previous posts, it is important not to forget how diverse the Allied armies were. The white European master race lost to the mixed multi-racial British Empire army, the segregated multi-racial American army and the Slavic Soviet army.
People are just people. There is no white superiority, if there was Hitler would have won the Second World War. There is no need to repeat the monstrous experiment.
How socialist National Socialism actually was is one of those issues to be debated forever.
The ambition to abolish Christianity is always the hallmark of authoritarianism, likewise the desire for the state to indoctrinate children instead of letting parents teach children their own ideas.
More superficially, whenever a vegetarian or teetotaler imposes their policy on the majority, I think of Hitler’s plan for his eventual joyless Empire.
]]>
Wikileaks has once again come up with some fantastic insights into how the elite run the world. Reading the different leaks from people associated with Hillary Clinton is fascinating. We are really getting a deep view into the globalist mindset.
The emails showing what Hillary was promising to her wall street donors are particularly enlightening.
If her actions and choices seem incomprehensible, you have understand that Clinton and her friends have a very different view of the world than us normal people. Especially those of us who hold to romantic ideas like God and country and loving your neighbours as yourself.
As always, click to enlarge the images.
Different crib

If you think that Hillary’s best known house, the house in Chappaqua, is pretty reserved and tasteful for the elite, it is, but you have to remember that this is not a ranch in the middle of the Texan desert, it is at the end of a private road in the suburbs of New York City. It is a mega-great house.

The house is surrounded by a large white wall, and a manned guardhouse stands by the entrance to the property. Yes, the anti-wall Clinton likes her own walls very much.
The red barn at the back is not for chickens, it is where her household staff and armed security are hidden away.
Meanwhile a small fleet of armoured vehicles provide suitable transport for any occasion.

Different services

In 2016 figures, the per capita disposable income of an American citizen is $39,190. Chelsea Clinton went to a school where tuition and fees cost $48,160 in 2016/2017. And yes, it has a massive green campus with a giant fence around it. The school campus makes Clinton’s house look like a hovel.
If Hillary doesn’t care about what provision is needed to handle mass immigration to inner cities, it is partly because she doesn’t need to use the overwhelmed schools or local services herself.
If Hillary seems a bit disrespectful towards the police, it is because she doesn’t need them, she has her own armed guards.
We can go on like this forever, so lets zoom out a bit.
Different Map
Almost every country has at least one thing to be proud of. As the British people, we are proud of our hard won freedoms and the communal institutions that our ancestors left us such as the NHS, our Royal Navy, our Royal family, our state school system, our ancient churches, castles, national parks and so on.
This means nothing to Hillary and their tribe, they are globalists because they are so rich they don’t want or need a nation state to look after them. From the first class cabin and the private jet, every country looks the same, the same hotel chains, the same exclusive shops, etc. The rich already live in a generic border free world.
If we draw a map of world according to Hillary’s email, it will look like this (map credit to Wikipedia, click on the map below to enlarge):
{kind=link}

How to run the world
The power structures of the globalist world view are really interesting but also quite basic. There are four levers they have to control the world. I will explain this using the above map.
- Trade policy
To Hillary and her ilk, California is the capital of the world, eventually drawing all of the Americas into a “greater California”.
By combining this Reino de Clintoñia with its two major colonies of Eurabia and Pacifica, we have a giant and generic service economy, ready to serve the elite’s every desire.
All the trade agreements like TTIP, TPP and the EU are there to make sure the servants do not become too uppity and to remove any barriers to the maximisation of profits for Goldman Sachs bankers and the others who fund Clinton and her friends.
- Patronage
As well as unifying the legal and trade systems, patronage is used to keep potentially dangerous alternate power structures such as intellectuals, religion and the media on board. Internal ‘markets’ and competition for grants keep the universities, NGOs and charities as useful idiots spreading the globalist gospel.
It is important to create pseudo-scientific pretences of why this globalist neo-feudal system benefits the population more generally, as opposed to more Occam’s razor like solutions such as lets take the rich’s wealth away and use it to cure cancer.
This is also why the current move towards cultural Marxism and identity politics suits the elite so well. David Cameron and the American democrat/republican one party state are happy to hand out gay marriage because it doesn’t cost them any money. Here have all the pronouns you want, just don’t ask for decent housing for the poor, infrastructure or services.
- Consumer goods and entertainment
2000 years ago, the Roman writer Juvenal coined the phrase ‘panem et circenses’ (bread and circuses) to explain how the elite kept the masses under control.
The classical theory of why the Roman empire fell includes the observation that through insecurity of trade routes and inflation, Rome stopped being able to provide affordable consumer goods to the people.
The global leaders today do not make the same mistake, they keep their servant class in check by exploiting the poor of the world. They keep Chinese goods cheap, and if the Chinese get sick of making plastic crap for the world, they keep plenty of other Asian countries poor as a backup, after that there is Africa, which is currently just used as a giant shop of minerals to be exploited.
[I have talked a lot lately in this blog about how Africa bears the brunt of the current system of world trade, so I don’t want to sound like a broken record, needless to say, every trade deal they make always includes massive tariffs against Sub-Saharan African countries.]
Meanwhile, we are in an entertainment golden age, no end of TV shows, films and sports are provided to keep the minds of the servants busy. While there is an attempt to reclaim costs to pay the cast and crew and so on, unauthorised distribution of media is rampant and tolerated as only thing worse than the people watching unauthorised TV is the people not watching it.
If the mainstream media is rejected by the people, then a major form of control is lost, thus the mad dash to control and censor the Web.
- Useful enemy
Whenever Clinton and other Western politicians get into trouble, Russia and a few other useful enemies are wheeled out as a useful excuse for pretty much anything.
There is a Goldilocks zone for useful enemies, not too big and not too small, Putin was getting too big for his boots so sanctions were used to make Russia’s GDP smaller than Australia, meanwhile Iran was on the verge of total collapse so Obama and Clinton recently removed its sanctions and bailed out the regime with billions of dollars.
Another way
We are finally at a level of technology where we can in our lifetimes, foresee a future free of disease, want or waste, where robots do the work and people are free.
After the Attack on Pearl Harbor, when FDR decided to pursue a war across two oceans, the US had no ability to fight a major foreign war on one front, let alone two. Yet he pulled everyone together, rich and poor, black and white, and together they got the job done.
Setting a national goal and putting the resources of the whole society into it can achieve massive things:
“I believe that this Nation should commit itself to achieving the goal, before this decade is out, of landing a man on the moon and returning him safely to earth.”
When JFK said the above quote, they had a general idea of the physical principles but no practical clue how to achieve it. We now know far more about cancer and other diseases than we knew about the moon in 1961.
I want a leader that says we will commit ourselves to curing cancer in ten years, to curing type 1 diabetes, to ending asthma in children.
I want a leader that says we are going to digitise our cars so that in five years time, the number of child deaths on the road is 0.
I want a leader that says we will build a house for every person who needs one, even if we have to take away a little land from wealthy estates.
What is not important

The whole reality TV side of things I don’t really care about. I don’t care if Jeremy Corbyn doesn’t wear a tie or Boris Johnson has made inappropriate jokes about foreign dictators. I don’t care if Labour MPs feel unhappy with Corbyn’s management style or Theresa May is alienating the 48% (which is now more like the 13% according to the latest polling but lets not get off track).
I do think it is somewhat odd that almost all of the Labour shadow cabinet come from London while almost all of the Tory Cabinet come from the home counties, but if they were the best people they could get, then I guess I don’t care.
I don’t care if Trump said something sexist 20 years ago, I don’t care if he makes his staff lose weight, I don’t care what he did when we was a billionaire playboy and a businessman.
I don’t care that the Clintons have a weird open marriage where, to use Hillary’s own terminology, she has to herd around Bill’s discarded ‘bimbos’. I don’t care how much Hillary swears in her emails. I don’t care she called her own party “a bucket of losers.” I don’t care if she coughs constantly for 8 years in a row.
I don’t care about temperament, I don’t care about who is the best manager. I don’t care who is the best husband or wife or mother or father.
I just want them to put these lilliputian tabloid issues aside and have some real policies to do something worthwhile for the actual voters.
Champions not tokens
The lives of the elite and the normal people are divided as never before. However, we don’t need leaders who feign the common touch. We don’t want token leaders, we want champions of the people.
Churchill was born into vast wealth, he was a drunk who gambled away the wealth of two great families and said many outrageous and sexist things, he would have probably been called deplorable and irredeemable by Hillary Clinton.
However, Churchill put all his privileged background and personal contacts into one aim, being the best military leader he could be.
When the time came that Britain was in the existential crisis of World War II, Churchill, being friends or related to much of the elite, knew exactly where their money was. The rich did not get off easy in cash terms and many of the Lordly estates were broken up. According to the national archives:
“a total of 14.5 million acres of land, 25 million square feet of industrial and storage premises and 113,350 holdings of non-industrial premises were requisitioned by the State.”
If we can raid the rich to defeat Hitler, can’t we raid them again to defeat cancer?

The last time I talked about the web browser, I was technically speaking about Iceweasel. For the last decade, Linux users like me have known the default browser that Debian ships under the name of Iceweasel.
In 2006, due to some hysteria over trademark protection and typical West Coast America “we know better than you” attitude, Mozilla told Debian it could not use the name Firefox or the Firefox logo.
Can we even use it here? Well since we don’t want to be told off by Mozilla’s logo police, we can use images of some beautiful people who have made their own dramatic and artistic costume interpretations of the logo. This blog is 90% about cool and silly pictures after all.
After 10 years of Debian using the name Iceweasel and its own logo, eventually, Mozilla gave up and asked Debian to use the normal name and logo. Lets celebrate with another costume:

Thanks Iceweasel for your service, we will miss you. LWM published a longer discussion of this change. Incidentally, Google’s Browser is still called Chromium instead of Chrome on the Debian Linux platform. I could only find one Chrome costume:

He (or she) looks pretty happy.
Meanwhile, this week Firefox 48 has been released which, among other things, has caught up with a feature that Chromium has had for a while, namely multiple processes.
Making the browser render web content or play media in a subprocess is obviously a win for security and performance, especially on Liunx.
Processes are the main native form of efficient resource allocation on Linux, so now Firefox is using multiple processes it is finally working with the grain rather against it.
It is still early days. Nothing has crashed for me yet, but I am keeping the Firefox that Debian distributes (which at time of writing is version 45), around just in case. You might want to consider doing the same, especially if you are using extensions which may not work in the multiprocess mode yet.
To try it out, download Firefox. By the way in my last post about Firefox, I talked about how to run multiple Versions of Firefox and how to create an extra profile, which might be handy.
Firefox is pretty cautious about turning multiprocess mode on but putting about:status into the browser will tell you if it is on or off. As in the image below:
If you find it is off, you can make a new profile (as I just mentioned) or you can open about:config and toggle the setting called browser.tabs.remote.autostart to true. Then you can go back to about:status and see if it worked.
It still might be off because of whatever reason, i.e. they it might break an extension or whatever. If you want to push on anyway then you have to open about:config again and make a new boolean setting called browser.tabs.remote.force-enable and set that to true. Find more instructions here.
So well done to all the Mozilla developers and volunteers who wrote and shipped that. Just for you, another of those great Firefox costumes:
 ]]>
]]>
Those who resort to violence, always lose their claim
After the 18th and 19th centuries, there were many competing territorial claims over former Prussia; Germany had some valid and some not so valid claims, as did other countries. Going to war (twice) over the claims was not valid however.
It is a long standing and basic principle of world order that the belligerent aggressor loses whatever claims they had. Now of course Germany is a peaceful and wonderful country and also makes no claim to any of these areas.

Whatever the right or wrongs of the Falklands issue were before 1982, once Argentina invaded and spilt British blood, they lost any claim to the islands; it is just how it goes.

It is also an issue of basic democracy that as recently as 2013, the Falkland Islanders had a referendum with a turnout of 91.94%, where 99.8% voted not to change the Islands’ status in anyway. The results of referendums must be respected, especially with such a high turnout.

There is also the practical matter that saying anything different will be a sure loser in British election.

Likewise, the question of whether making the state of Israel was the correct response to the evil of the holocaust, became a non-issue after 1967. Israel did not start the war, the Arabs did, but the Israelis won the war and the issue was settled.
Any claims the Arabs had over the land was lost then. You don’t get to claim territory through starting wars, you must only lose by starting wars.
Time to boycott calling for boycotts
Even if you disagree with Israel’s policies, collective punishment against its citizens can have no practical effect on those policies.

Dis-inviting an innocent academic from a conference, will not change policy. A professor of Artificial Intelligence or Manuscript Studies (made up examples for the sake of argument) does not set Israeli security or foreign policy.
If a UK institution chose an Israeli company to provide a product, it did so based on price and quality. Pressuring an institution to boycott the Israeli company will just make innocent workers there poorer and will mean the UK institution will get a higher priced and/or lower quality good. An orange juice producer or a software company does not set Israeli security or foreign policy.

The same principle applies to exports. Pressuring a UK company to not sell products to Israel, tractors for example, will not change a single Israeli policy. It will just mean they buy a tractor from someone else and workers in the UK have less jobs making tractors.

Discretion is the better part of valour

The sad truth is that there is nothing the UK can usefully do to make peace in the middle east. Tony Blair of all people tried to be a peace envoy and yet there is still no peace.
Any politicians that want to pander to either Muslim or Jewish voters by taking a side are just being dishonest with the voters. The UK just has no leverage on either side. The Middle East is just not a part of the world that cares what Britain thinks one way or the other.
Our winning strategy as a country is not to pick sides and just be a friend to everyone, and of course, sell them all our goods and services.
By the way, America has far more clout, expertise and money and still has not made much progress either but that is another story.
Yes there are poor and suffering people in the Middle East, but there are poor and suffering people everywhere so we should focus on areas where we are wanted and we can have a meaningful impact, such as African free trade and development which we have ignored for too long.
It is not our fight

So it total baffles me why Palestinian liberation or Latin American politics are cause celebres on the UK left. There are no votes to be won here.
We talked before about the difference between few hundred thousand people in the UK who have strong political views and the millions who just want cake.
The average British voter does not care a monkeys about Palestine or improving Anglo-Argentinean relations and just wants to hear domestic policies.
It seems like Jeremy Corbyn is wise enough to know that there is a difference in being a backbench MP who can obsess about these obscure issues and a potential Prime Minister who needs to have total clarity and focus to cut through a hostile media. I hope so anyway.


On the 23rd June 2016, the people of Great Britain and Northern Ireland were asked whether they wanted to leave or remain in the European Union. 52% voted to leave while 48% voted to remain.
On April 10th 2016, ten weeks before the vote, ICM published an opinion poll that gave a four-point lead for Leave (52% vs 48%), which turned out to be the correct result.
One explanation is that with several pollsters covering the referendum, one has to be right; after all, even a stopped clock is correct twice a day.
However, lets consider an alternative explanation, that the whole EU referendum campaign made absolutely no difference to public opinion at all.
Hundreds of millions of pounds spent by the campaigns, posters, Boris’ bus slogan, acres of newspaper columns, billions and trillions of tweets, all of it, didn’t manage to convince anyone of anything.
People are just not that into politics.
In other words, the day to day minutiae of events doesn’t really matter to the silent majority, they haven’t got the time or the inclination to care and why should they? It would be very conceited to say the people should look up and spend their time listening to their Lords and masters.
The print circulation of Britain’s main broadsheet newspapers has fallen so far they can barely scrape a million per day combined. What percentage of their remaining readers do more than browse the news before going straight to the crossword or the sport section?
Meanwhile, less than 200,000 people in the UK watch the BBC’s political programmes, but over 15 million people watch ‘The Great British Bake Off’ on the same network, which is a cake baking competition.
As I said on Twitter: Politics is important. However, cakes are 75 times more important.
In fact, I don’t want to ever live in a country where politics is more important than cake, it doesn’t sound like a very benevolent regime.
 ]]>
]]>
In the midst of a larger post about the results of the EU referendum, I talked about the echo chamber in the campaign. I want to explore that a tiny bit more.
You also may remember that in a post before the referendum, I talked about myself as an undergraduate and how I was very passionately pro-EU but over time, the doubts set in, especially after the crash in 2008 and the EU’s harsh measures metered out to Greece.
As I started 2016, the doubts and problems with the EU had not yet pushed me into the idea that the UK should ever leave the EU; I started 2016 as a reluctant but firm ‘remanian’.
However, I wanted to make the decision based on all the information and up to date arguments. I turned to other people, both on Twitter and in the real world.
I soon ran into a problem, even discussing my own doubts was beyond the pale with anyone pro-EU, you must support the EU because that is what you do.
On Twitter it was worse, loudly unfollowed by 20-30 people, regularly blocked in the middle of a seemingly civil discussion over a technical EU matter.

I was shocked the first time, saddened the second time, third time it was water off a duck’s back, I stopped noticing or caring when someone threw their toys out of the pram.
I did try to carrying on to discuss with any remainian who wanted to, in the hope they would come up with the magic argument that would put me squarely back in the remain camp. It soon became apparent that everyone else has the same doubts and concerns.
Unlike ten years ago where you could easily encounter British Europhiles who wanted to join the Euro and the Schengen Area and so on, now ardent Europhiles seem a bit thin on the ground.
I met no-one that had a positive view of the EU as a force that will make things better, it was just what you did about the faults, whether you just lived with them in a fatalistic fashion or tried to face up to them by leaving (and potentially making a lot of new issues/opportunities).
A lot of the remain argument was that uneducated and poor people want to leave, so don’t be in that group since they are all racists and bigots. Well I was brought up in very modest circumstances indeed and these are my people and I don’t recognise that description.
Meanwhile, the leavers were just more fun and upbeat people. They were happy to listen, discuss and gently point out their views.
I guess the morals of the story are that if you want to campaign for something, have the most hopeful message. Even if you are against something, have the best plan for fixing or replacing or leaving it behind. Blocking people doesn’t win votes in real elections.
Above all, the moral is Twitter is probably a crap place for discussing politics.
]]>
The EEC was not very popular when the government took the UK into it in 1973 and so the government was forced by the voters to have its first leaving referendum only two years later in 1975.

The government and all of the media threw the kitchen sink at remain in and succeeded, but on practical grounds alone, it never even tried to sell the vision of an ever closer union to the people of Britain, and if it had, it would have been rejected.
While governments managed to resist another referendum for the next four decades, the practical nature of the remain argument meant there was no mandate for further integration, indeed the remain argument was won precisely on the basis that Britain would not be pulled in any deeper.
So as the EU project developed in different directions, Europe was not something Britain did, Europe was something done to it; something that had to resisted or opted-out of: Schengen Area, the Eurozone and countless other programmes.
The 2016 EU referendum was the the last moment in history that a pro-EU case could be credibly made but again the establishment decided not to make it. It again decided to focus on the perceived practical shortcomings of an independent UK.

In other countries, there are some people who genuinely believe in a United States of Europe. However, we in the UK never had that tradition, so those arguing for remain are those who benefit most from the patronage that results from laundering our own taxes to and from Brussels give.
Brussels is awash with lobbyists for non-European interests and yesterdays winners struggling with technological change, wanting to game the regulations against new interests.
Remain was a coalition between decent people wanting to keep the status quo but also all these aforementioned parasites and spivs who know they could not justify a policy or an item of government spending to the British electorate so abuse the (still not very democratic) EU to sidestep democracy to push their own special interests and regulations.
I said before the referendum that the rationale for entering the EU in 1973 was marginal at best and I concluded the forces moving the UK away from it were increasing.
The neo-liberal/Thacherite consensus of the last 30 years cracked fatally in the 2008 crash, since then it has been on life support as near infinite supplies of money are printed and dished out to the banks, but brain activity has not returned to the patient. The EU referendum is the British people starting to turn the machine off.
To put it another way, as I said on Twitter, it was Chekhov’s referendum. David Cameron put a gun on stage and the people shot him with it.
After the vote, I talked about the call for the second referendum and why it will not work, Brexit has just sped up the inevitable changes.

Anyway Britain is leaving the EU. If you voted for remain, not only will be much happier if you just accept it and move on with your life, you will be more successful. Escaping to a fantasyland where the vote did not happen will mean you miss the opportunities of the future.
This applies to organisations and sections of the economy too, after all no one is owed a living.
Those that work in harmony with the new independent era will thrive, those that mope around re-fighting yesterday’s narrative will be seen as irrelevant in the post-Brexit era and thus will lose funding accordingly.
The leave supporting public has been gracious in victory, trying to bring everyone on board. However, the good mood will not last long if institutions are seen to be working against the UK. David Cameron and George Osborne doubled-down on Remain and their position was untenable in the new era. Those that don’t learn the lesson might suffer the same fate.

I think in the long term, Brexit will be a benefit to all of Europe, Britain has gone from being an unhappy tenant of the EU to Europe’s most supportive neighbour and ally.
If you are a European, we the British people, voted to take by control and run our country from Westminster and our city councils and regional parliaments in the UK. However, we still love you as people and we love your countries. We can still kiss you from over the fence.
]]>
The leave side had Boris’s battle bus which had the slogan “We send the EU £350 million a week, let’s fund our NHS instead.”
While it is technically true that the cost of the UK’s soon to be ended EU membership is £350 million per week, we got a rebate (i.e. a discount) of £100 million so we only sent £250 million per week. While it is not stated in the slogan how much exactly extra money could be available for our NHS, it cannot be £350 million per week, since only £250 million per week ever existed (to the extent that money exists).
For me, the question of whether to be in the EU or not was never about money but the slogan would have worked as well with whatever the correct fact-checked figure is.
However, if it was meant to be a trap, it worked. The remain side had far more money and far more establishment figures, and when it constantly sent those figures out to say that the real number is really £250 million per week and some of this is spent on useful things here in the UK etc, it is made leave’s case for it.
For £250 million a week is still a massive number and the same order of magnitude, by focusing on the detail, Remain left the overall premise unchallenged.
Having your opponents make a point for you, frees up your own resources and own airtime for other points.
Not that it matters, as no one was listening. People voted for their own reasons not because of anything Boris said.
]]>
This is a sequel to the last post about Britain’s relationship with the EU. That ended with the conclusion that “However, we will leave in the end, it is just a matter of time, and we will not be the only ones.”
Little did I know that the people of Britain were already there ahead of me. When the BBC’s coverage started under Britain’s leading presenter, the great David Dimbleby. It seemed that the Remain side was going to cruise home.
I thought, okay a noble fight, we made a point, but the forces of multi-national capitalism were overwhelming. So I went to bed. After all the two campaigns were not equal.
A lop sided campaign

The Remain side had all the forces of multi-national neo-liberal capitalism, the banks, the European Commission as well as implicit support from the supposedly independent Bank of England who popped up occasionally with helpful statistics and reports.
A lot of people do their duty as citizens and vote, but are not really interested in politics. They have enough on their plate with work and family etc. These people were always likely to do what they were told by the political leaders and also are biased towards the status quo.
The British government spent £9 million on posting a Remain booklet to every house in the UK, a benefit that the Leave side did not get. We also had the Prime Minister and the leadership of the other mainstream parties like Labour, SNP and Greens supporting Remain.
The support of the Labour leader Jeremy Corbyn was particularly difficult as the traditional left wing position in Britain is to be against the EU. The 1975 referendum, the No campaign was led by the main Labour figures of the day Michael Foot, Tony Benn and Barbara Castle.

Jeremy Corbyn was a well known eurosceptic but as the leader of the Labour party, whose MPs were mostly elected during the Blair years and thus are mostly right wing, he was in a bit of a difficult situation. So he did his duty as party leader and represented the party line, appearing at events all across the country for Remain.
He did however refuse to make any out and out lies, and so when cornered with a particularly forensic question, the truthful answer was not always the most politically helpful answer for the Remain side.

The mainstream media were very pro-remain at first, especially the publicly owned TV stations like the BBC and Channel 4, but the newspapers started to drift away, even the Guardian started featuring a few pro-leave articles in the last week or so of the campaign.
Moving from one newspaper to another is a matter of moving your hands a few centimetres, so British newspapers do tend to reflect the views of their readers to a certain extent, despite the owners tending to be pro-Remain.
How to get someone out of bed
However, after a few hours of occasionally checking my phone in a sleepy haze. Something was happening. Was I dreaming it?
Area after area went for Leave. London and its little spider legs of wealth around London were going for Remain, as was Scotland, but the rest of England and Wales mostly voted for Leave.
I decided to get back out of bed, go back downstairs and wait for the Birmingham result.
Birmingham is for leave

Britain’s second largest city, Birmingham is not some twee ancient town like the nearby Anglo-Saxon capital of Tamworth (see last post). Birmingham is a child of the industrial revolution and the Empire (also see last post) with the major expansion of the city in the 1800s and early 1900s. Birmingham is a beautiful city, as long as you like Brutalist and Modern architecture.
Birmingham is somewhere between 45% and 50% “White British” (this weird term is the designation the government uses), it isn’t the most diverse city, which is Leicester and some the cities of the North but it is the one I live in and know best.
The different races of Birmingham mostly get on very well, the city’s signature dish is the Balti and the civic institutions put on events that reflect the city’s diverse cultural backgrounds but are open to all.
It is a Labour city. The right wing parties barely make a foothold, there is no UKIP presence to speak of. There are 9 Labour MPs and just one Tory MP in the outer suburb town of Sutton Coldfield, which doesn’t even consider itself part of Birmingham.
Birmingham with its 700,000 registered voters in the main city area, was expected to be a big remain landslide. When the result came it was 50.1% for Leave.
When you go through the posher areas of Birmingham, there were loads of Remain posters on many of the large expensive houses, so it is not mathematically possible or likely that all the votes to Leave were from “White British”. So the Black and Asian voters of Birmingham were split in the same way as the white voters, or at least enough to put Leave over the top.
The question that Remain will never answer

I focused last post on the successful non-EU immigration that the UK has had, and a good proportion of them seem to have gone for Leave, as I thought they would. One of the questions I posed in my last post can be summed up as follows:
Why should a Bulgarian be able to bring their family to the UK and trade freely, but an immigrant from India cannot?
Despite being posed many times by Leave, this question was never answered by the Remain side. Therefore, the Black and Asian vote split and the Leave side benefited from a million or two more votes nationally, which is of course a winning difference.
Why didn’t Remain field an answer? For four reasons I think.
Little Europeans

Firstly, is the ‘little Europeans’ issue I talked about in the last post, the culture of the EU is about middle class White-European people flying about between cities on expenses. Britain has a Commonwealth history making us look at the world, a lot of Europe does not.
Those Britons most in support of Europe tend to have this identity also. The idea that people from outside the EU such as Africans or Indians are equal to Europeans, and therefore the system should reflect that, just doesn’t occur to them while hidden inside the walls of fortress Europe. We might as well be talking Klingon for all the good it does. There is just not the mental framework there to get it.
Remain also just assumed that all non-“White British” were theirs by right and they did not have to work for it. The idea that Asian or Black voters would have independent ideas and issues that should be considered did not seem to be considered by Remain.
Secondly, the Remain side I think made a tactical decision not to answer the question. They thought saying something like immigration is good, we should open our borders to the Commonwealth too, but we are not going to control EU migration at all to compensate, would push more people to the Leave side.
Top down Remain, bottom up Leave

Thirdly, because the Remain side inherited the infrastructure of the Labour and Tory parties, they followed a lot of top-down practices that made sense in a constituency first-past the post based system. So they sought to get a simple majority in each area, rather than focusing on total number of votes. They assumed that most Midland and Northern cities as well as Wales, would overall go for Remain so didn’t put any real effort into those areas.
Meanwhile the Leave campaign, short of financial resources, had to run a grass roots, bottom up campaign. They found out the questions putting people off Leave and had to come up with some kind of answer to the questions.
Meanwhile, several Unions like the RMT, ASLEF and BFAWU; left-wing anti-establishment figures like George Galloway and Julian Assange, as well as the socialist worker and many others, were rallying the non-mainstream media, blogs, and social networks to the Leave side.
How to brainwash yourself

The forth reason is connected to the last part, and the most important issue and this is a wider reason to why Remain lost. They believed their own propaganda, they brainwashed themselves. Believing that there were no valid reasons want Leave apart from to control immigration, they didn’t field any answers to the questions being raised.
Remain just focused on two messages:
Project Fear - leaving the EU would be the end of the world. The Chancellor George Osborne, previously featured on this blog, the one that likes to take money from disabled people and give it as tax breaks to billionaires; he made a much lampooned threat of an emergency budget requiring massive tax rises and spending cuts.
Meanwhile there was the even more preposterous argument that the UK leaving the EU would be the end of peace in Europe. I don’t even know what this means. Are Germany going to restart the blitz and rain down bombs on our heads? Is the UK going to gather an army of longbowmen and retake Agincourt? What a lot of utter nonsense.
Project Sneer - anyone who is for leaving the EU is a racist Nazi who wants to round up immigrants and throw them into the sea. Equally stupid. We will talk about this again shortly.
While immigration was an issue of course, the Leave campaign also focused on many issues that were not immigration including:
- TTIP which does actually include healthcare and results in the break up of the NHS and private health insurance from American companies
- The issue of little-Europeanism/racism we just talked about
- The fortress Europe that makes it difficult to trade with non-EU countries which are the growing part of the world.
- The lack of democracy in the European institutions. Only the Commission can introduce laws and repeal laws. The elected European Parliament can just discuss them. It has about us much power as the fantastic UK youth parliament where school children go into the house of parliament and discuss laws.
- The focus on complex regulations instead of Common Law
- The economic and social punishment given by the EU to Greece (see last post)
- Unemployment levels on the Continent.
- You could go on and on.
- The way the EU’s Thatcherite policies help distort the allocation of resources towards London and the Financial sector and away from manufacturing and wider England.
Birmingham is a traditional capital of manufacturing, and still has the productive capacity hanging on for when Britain starts depending on making and selling things, rather than relying on financial scams for its national income.
I wonder if this had a lot to do with why Wales voted Leave. The EU is keen to spend our money on museums, University buildings, and so on. But anything that might give areas like Birmingham or Wales a competitive manufacturing advantage is not allowed. Just look what happened recently to the Port Talbot Steelworks, EU regulations stopped the government from acting to save this vital national resource from Chinese steel dumping; steel is the foundation of national defence after all.
Echo chamber

The Remain side acted like an echo chamber. Its core message of sneering at everyone that is not an EU-supporting cultural liberal from Cambridge or London cost it dearly. The remain side followed its own supporters on social networks, it did not engage with the non-mainstream media of right or left, it did not go out and listen to people’s reasons for Leave and provide an appropriate response.
Therefore they lost.
Ignoring the merits of the argument for a moment, the Remain campaign, despite every possible advantage, managed to misstep at every possible moment. From Osborne’s terror budget to trying to make political capital out of the tragic death of an MP, there was not much self-awareness.
Piling on the war monger Tony Blair and everyone responsible for the 2008 crash did not improve their credibility.
Consumers in denial

When the result came, many tears were cried and much gnashing of teeth by Remain supporters.
Several days on, the vestiges of Remain support are still in full on denial. By not listening to voters in England and Wales outside London and its small tentacles into the home counties and the University cities of Oxford and Cambridge, they were totally dumbfounded that the country voted against them.
Democracy is not about ordering a policy like a pair of shoes from Amazon. You have to listen, you have to engage, you have to convince people that are not like yourself, you have to build a coalition of support.
Mocking people and blocking people on Twitter does not constitute productive debate. Calling people racists or stupid does not move them into your camp.
Second Referendum

The biggest joke of all is the idea of a second referendum. The people who did not and will not listen want to have another vote and keep having them until they get the result they want.
The Leave side had to wait over 40 years for a referendum. The Remain side want one tomorrow.
This will not work.
Firstly, this referendum was extremely expensive in staff costs, venue costs and lost productivity as schools and other public buildings are closed. All elections are expensive and take a long time to organise. Being based on the popular vote, it is a bit more complicated than the normal constituency system that we are geared up for. Normally there are lots of safe seats that never change and have massive winning margins that don’t really require much precision or huge amounts of staff.
Secondly, a lot of advantages the remain side had will no longer exist:
- David Cameron quit and there will be no pro-remain Prime Minister again leading the charge and offering potential promotions and knighthoods etc for those on his/her side.
- Everyone is knackered. Labour and the Unions spent all their campaign budgets and desperately need to save cash, energy and volunteers for the next set of local elections and a possible snap general election. Campaigners from other institutions like NGOs and companies need to go back to their real jobs.
- Project Fear is over, the British public already voted out and are no longer scared. Those who felt they had to ignore their heart will not need to do so again.
- Project Sneer is ineffective because anyone previously scared of talking about being out for fear of being seen as a racist or UKIP supporter, has nothing to fear as they are with the majority 52% and rising.
- Any new referendum will be from the outside. The status quo will be for remain out. The only people still for out will be a coalition of cultural liberals and dodgy bankers.
- The EU has had enough of us. When they say Britain is toxic and causes contagion, it means that other countries want the special deals we have had like vetos, partial rebate, no Schengen, no Euro. They think the sooner we nasty Island hobbits are at arms length, the longer they can keep the EU from collapsing. They are deluded of course, but that is a discussion for another post.
- Events - lots of nasty crap is coming down the pipe for Europe, it will look more unattractive as time goes on. Also other countries may leave.
- Demographics - Non-EU migrants have the highest birth rate. So as the years go on, ignoring the world outside and the issues we talked about above becomes more untenable.
- No More Patronage - the UK will now need its own systems for funding Universities, research, regional development, farming, etc. People will adapt to them and will no longer feel tied to Europe by an umbilical cord of funding.
- Progressive policies - the UK will increasingly find solutions that are not legal or tenable in the EU. Rail nationalisation, student scholarships, NHS re-nationalisation and so on. Once setup, they will act us as a permanent lock keeping us out of the EU.
If we run the referendum again, it will just be embarrassing. Leave will get 70%, or maybe much more, if we are already out then 80% or 90% I can totally believe. We need to save our fellow citizens from self-harm and mental anguish and just say no to that.
This is my design

I don’t deny that Leave vote had white bigots, but it also had socialists (like me) and a good amount of BME population outside London.
In any case, the past is the past, we are on the way out.
The far right bigots will get a shock when it finds that the independent UK actually increases immigration as it booms free of the EU. This time our immigration policy can be race and nationality blind, allowing the whole world to come here on an equal basis, especially the Commonwealth countries who sent 4 million of their citizens to fight and die alongside us in World War II and whom we have treated terribly since.
I love Europe, I just don’t like the centralised Roman Empire style state (see last post). I want the UK to engage with the EU countries on a bi-lateral basis, and on the level of people and companies, as a real union of peoples, not a neoliberal cage where everything has to go via a centralised Brussels bureaucracy. I also want the UK to lift its eyes and interact with the wider world.
This is our chance to do things differently. As we replace EU run areas with local ones, we can upgrade them with modern values and technology.
Our farming and fishing policies can have the greatest environmental standards in the world. We can finally ban battery chickens and give incentives for Organic food. We can stop the nonsense of paying people not to produce food and instead pay them to upgrade their animal welfare and environmental standards.
Our research policy can focus on devolving funding to the Universities themselves, trusting them to invest in long term research projects. Get the professors back in the lab and the lecturers back in the classroom, rather than making them spend all their time bidding for short-term grants.
We can return to making and not depend on the financial scams for our national income.
We can increase the minimum wage to a real living wage and thus encourage the use of automation, machines and robots (see end of last post).
The excuse in the past was that if we could not give our young people full scholarships to University, because it would be untenable to offer them to the whole EU. Now there is no excuse, we should give all young people a scholarship so they begin their careers with skills and knowledge not debt.
Boris’ Britain

Birmingham’s own Giesla Stewart was the voice of reason in this campaign and the official leader of the Leave campaign. Giesla had a good campaign and did very well. However, the mainstream media only wanted to show Boris.
I must admit Boris also had a good campaign. He didn’t make any gaffs and he looked like a leader, he stood up and took the incoming flack from Remain and effortlessly outflanked his Tory opponents by pivoting to the left when required. He seemed very comfortable and statesmanlike sharing cross-party platforms with Labour Leave figures such as Gielsa, Kate Hoey and others.
Meanwhile David Cameron refused to debate his opponents and looked like he was afraid. The remain side didn’t manage to combine the two campaigns very well.
Boris is going to win the Tory leadership, it will probably seem like a coronation, then he will try to bounce a snap election and get a strong mandate and he may win.
The left need to stop moping over the UK’s European exit and unite or Boris will get a landslide.
We can make the progressive case and win the next election. We can stop Boris’s Britain and make Britain a progressive country once again.
I would like to tell you a story. This is a story of how we the British people, and we the planet, got here and more importantly where we should go next. It is still a work in progress. If you are of a like mind, please help me to improve it. [1]
Dogglerland
After the last Ice Age, Britain was certainly a part of Europe, the Thames and the Rhine met and Woolly Mammoths and later people walked across to Britain.
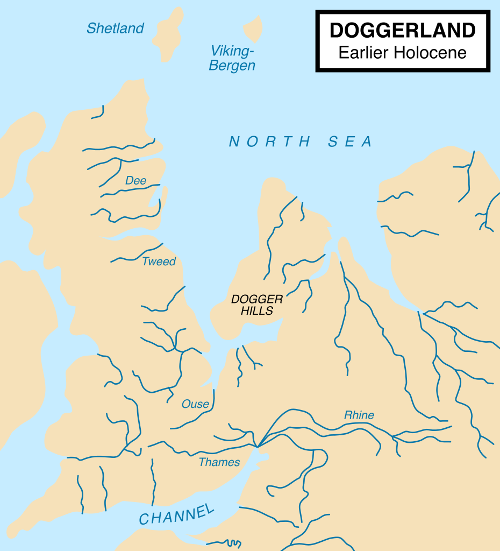
However, God decided out of wisdom or for a joke, that Britain should be an island and smashed the land bridge with the Hammer of the Waters [2].
Of course, throughout history, idealists have been trying to glue Britain back onto Europe, without much success.
However, this unavoidable geological and geographical fact remained and still remains, and it gave us a very different history to the continental peoples of Europe. I think it also gives us a very different future.
Rome DOS
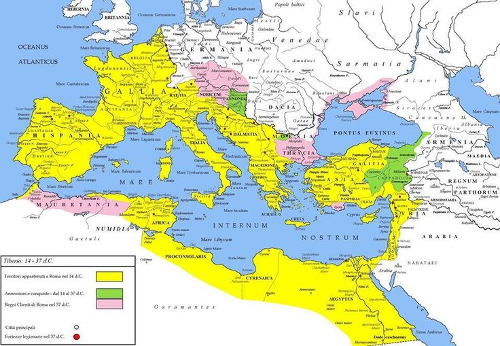
Julius Caesar’s made expeditions to ancient Britain in 55 and 54 BC, it was the beginning of a pattern. The Romans could enter Britain and conqueror territory, but they could not hold it.
Whether is was Boudica, the Iceni queen who burned down the Roman settlements at modern day Colchester, London and St Albans; the inability to make progress in the North, modern day Scotland, Wales or Cornwall; or countless other defeats; the Romans never achieved a stable position in Britain.
Roman Britain existed within its urban colonies but despite a massive investment in infrastructure, such as the famous road network, conquering Britain was never a serious enough priority to divert the required military forces to subdue the people of Britain once and for all.
Roman officials and retired veteran troops settled in Britain had a tendency to go native and side with the locals over Rome, not least for survival, intermarriage with local tribes brought more security than the Roman state, which was more annoyed than responsive when the frequent requests for rescue came. After a few hundred years of half-hearted efforts of colonisation, Rome stopped answering altogether.
Charlemagne and Rome 3.11
However, in Europe, despite the collapse of the Romans, the Byzantine and Frankish Kings were trying to recreate and hold the Roman Empire, Charlemagne being the most famous, he conquered a good part most of Western Europe.
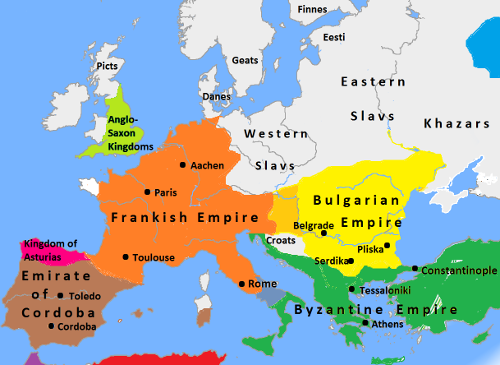
For those on the continent, they have a 2000 year process of recreating the Roman Empire. However, we were barely in it to start with, and haven’t joined since.
While Charlemagne was winning battle after battle, back in Britain, something very different was happening. As the Romans had faded out, the Saxons faded in, it wasn’t very long before the Mercian Supremacy united England under the Saxon Kings and their capital of Tamworth.
Normandy
William I, also known as William the Conqueror, the first king on the back of the space-limited 1 foot rulers traditionally given to British schoolchildren, was cousin and in his own mind at least, heir, to the previous king Edward the Confessor.
With the arrow through King Harold’s eye, the Anglo-Saxon era of Britain had ended and the Norman age had begun.
Despite Northern France being their ancestral homeland, the Norman Kings and their Tudor descendents failed to hold together England and France, losing Normandy and the rest of their homelands to the Franks.
They had more luck in the westerly direction, conquering the various little kingdoms in Ireland by war and marriage, while Henry VIII managed to create a peaceful union with Wales. However, all attempts to secure a legal heir either by legitimising his son Henry FitzRoy or divorcing required permission from the Pope.
English Independence from Rome 95
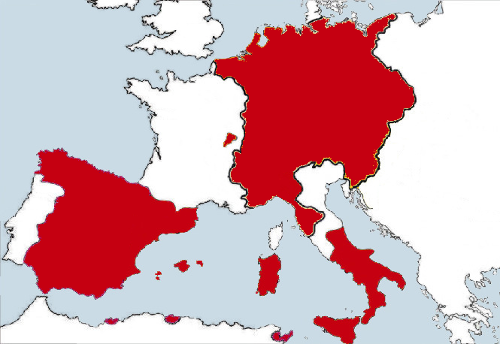
The Pope had bigger problems than pleasing the English (and Welsh and Irish) King, Emperor Charles V was once again building a united Europe. Grumbles about papal rule and (in practice) subservience to the Holy Roman Empire had been bubbling for many years in parliament over a range of issues, but the international marriages of the King had always meant the monarchy was a limit to how far parliament could act.
Now with the King on the side, the Acts of Supremacy was could be passed, meaning the King and the secular parliament would now rule the Kingdom, the role of the Church was confined to moral matters alone, and England was no longer seen as a minor partner or dependency of the Holy Roman Empire.
This also enabled union with protestant Scotland, and James VI of Scotland became James I of England. Despite the movie of the evil English killing poor blue painted Mel Gibson and the moans of today’s Scottish nationalists, it was actually the Scottish that (peacefully) conquered England.
The United Kingdom was now a confident and powerful country. Freedom of thought led to the industrial revolution, which we will come back to later.
Catholic Europe and its supporters did not take this lying down, England was still a valuable prize to add to a European empire. The Spanish Armada was the most famous failed attempt at an invasion, and the Gunpowder Plot tried to blow up parliament with James I inside.
Two last attempts at UK-European integration
A more consensual(ish) attempt of European integration was when parliament invited William of Orange to become the King William III and so he did. For a brief period it seemed like the United Kingdom and the Netherlands would become one country. However, William was childless when he fell of his horse and died, and each Kingdom had different rules over the succession, and that was that.
Next in line was his sister in law, Queen Anne, the last truly English monarch. Under her rule there was a major humanitarian crisis on the continent. King Louis of France decided to commit genocide against the Huguenot people and wipe them out in a series of massacres, half a million left France in a giant exodus.
Queen Anne opened Britain’s borders and 50,000 Huguenots moved here. Queen Anne’s new immigration policy was simple, anyone who turned up and pledged allegiance to the Queen was immediately part of the British population.
The open border policy lasted for hundreds of years. The barriers were only put up fully in the late 20th Century, when we were already in the European Union.
Anyway, like William, Queen Anne also died childless. What happened next is quite interesting. Parliament chose the next King from a list of potentially suitable Princes and Princesses. They settled on George of Hanover, the 58th in line to the throne and non-English speaking.
We were now in a union with a mid-level German principality, but like all our other European alliances, it broke down and it eventually the Kingdom of Hanover became part of the German Empire.
Britain in the World
By now Britain had lost interest in European affairs, we were part of a global Empire on which the sun never set. Lots of terrible evil things happened, which everyone talks about but also some good things, which people don’t talk so much about.
On a purely economic level, the Empire was a giant mistake. What started as an attempt to get a set of sustainable safe ports ended up covering a quarter of the world. It was the industrial firms of the UK that had to subsidise the infrastructure of Empire building, and as other countries got their industrial revolution, the sums no longer added up.
If we had just defended these ports, and given countries their independence quicker, would they have been more free? Or would an even less benign European power have swooped in and taken them?
Anyway, the Empire and all its good and evil and idiosyncrasies happened. The Commonwealth is there? Why do we ignore it?
We discovered medical treatments and we started Canada, Australia and New Zealand. From a small patchwork of feudal kingdoms, we united India - against us of course - but now it is one of the greatest countries in the world.

Obviously we cannot take credit for India’s hard work but we did leave them the world’s largest railway, Westminster-style parliamentary democracy and the English language which they are using brilliantly to trade internationally, they are the winners.
The Commonwealth is the growing part of the world, the 21st century is their century. Why shut them out just to stay in a club of losers? Lets get stuck in and help the Commonwealth countries develop. The old masters can become the servants, lets not be too proud and have some humility.

The Empire was not a one way street, we learned a lot from the Commonwealth peoples. We got tea, carpets, colourful patterns and new artistic and musical forms, new philosophies and our national obsession with curry.
By being exposed to the world, the values of the British people started to change. We realised that people were not so different. We went into the world as gold-hungry pirates but started coming back with new values.
The Society for Effecting the Abolition of the Slave Trade started from those who had gone out into the Empire and not found blood thirsty savages, but instead found friends and lovers, decent human beings. To make sense of it they went back to the New Testament notion that God made all men are equal and all men are our brothers.

This came to a head when the great Christian leader and parliamentarian William Wilberforce led the social and parliamentary campaign to abolish slavery.
Since everyone is our brother and sister, all men should be made free of slavery, oppression and poverty and it is our responsibility as human beings to make it happen, to bring freedom to the world. Not wait for the oppressed to take back their own freedom, it is everyone’s job, especially the advanced country that is Britain.
This sounds simple and obvious now, but in the late 1700s this was a radical idea, the first time it had been exposed.
It is an unavoidable historical fact that this was a British (and Dutch) movement. During this period, Germany and much of continental culture was going in a totally opposite direction, building the foundations of fascism.
I don’t say this for nationalistic reasons but to point out that human rights did not start because of the EU. We were already starting to take a first step down this path three hundred years ago.
Maybe this is why God brought the hammer down on Doggerland, to give us a more global perspective. Once you have built a boat to sail to Europe, you can use that same boat to explore the world, then you find that everyone is a human being.

The last patriot
American Independence is today framed as a fight for freedom, Mel Gibson being killed (again) by the evil English, and to a large extent that is accurate. However, what they don’t like to mention is that one of the factors driving American Independence was a fear among American slave owners that Britain was going wobbly on slavery. They were right, we were.
What is also true is that the newly independent America went backwards on the rights of Black people and native Americans for the first 50 to 75 years.
One thing that the British navy based in its territory in Canada liked to do was to go down to plantations in the American south and rescue slaves, many thousands of whom settled in Canada and in the UK.
We should have done more. We should have freed every last slave, even if it meant abolishing the US government and killing Mel Gibson a third time. All people are equal. Those who are oppressed we must help.
All Britons got free healthcare in 1948. If you are black in America today you are three times as likely to not have decent health insurance than a white person. America was 75 years behind us in 1800 and it is still 75 years behind now.
Therefore, this is not the time to import the US health care system via TTIP. Sadly, the EU has it on the cards and we cannot escape it while being a member. If you or your family has what the Americans call ‘pre-existing condition’, then expect significantly worse and more expensive healthcare than we have now.
I actually love Americans and American culture. I hate their war mongering governments. I love San Francisco and hate Washington DC.
We should have free trade with America, but at the moment the American government is only offering take or it leave it terms. I think we should leave it.
I also dislike the idea that to criticise the American government is a problem. I don’t want to live there. I don’t want UK to become America either. I don’t want their ideas about private healthcare, GMO foods, Fracking or a culture based on the ownership of guns.
Rome XP: World War I
When Napoleon tried to create a united Gallic Europe, we were going to lose our essential pit stop of Malta and possibly lose access through Mediterranean, as well as our allies being attacked.
So we popped over the channel and put Napoleon is his box but lost interest afterwards. As we saw above, we long ago lost interest in holding possessions on the mainland of the continent.
So after Napoleon, it was still France that was seen as the potential trouble maker. In general, in the 19th Century, Relations between Britain and Germany were very good. Back then Britain still believed it was a Germanic people, the Anglo-Saxons, and we had our recently imported German kings. All that was deliberately and rapidly washed away in the build up to World War II so it is quite hard to comprehend now.
Our main priority was always free trade routes, as long as we could go past Europe through the Mediterranean, we didn’t want to interfere in the continent and they didn’t want to interfere in our empire, we just wanted happy neighbours.
However, while we were sailing off around the world, causing chaos, building railways, drinking gin and rethinking what it was to be British and human. The Europeans were still trying to make the Roman empire. They couldn’t agree if it would be a French empire or a German one but now they had better guns which spiralled into World War I.
The Austrian Franz Ferdinand was assassinated by Serbia. The UK tried to make France and Germany just get along. They didn’t listen. Politicians and generals on both sides decided this was the perfect excuse to defeat the other and become the new Roman empire.
When German and France started fighting, we still tried to calm it all down. The problem was that Britain a had given security guarantee to Belgium in 1839, not sure the UK even remembered but the Belgians did. So when on the 4th August 1914, Germany troops marched through Belgium to attack France, the guarantee was triggered.
The British public was totally confused, weren’t we a Germanic people? Isn’t France the country of Napoleon? Aren’t France the bad guys? Why do we even care about Belgium anyway?
In the confusion of complex European politics, to the government honouring the deal with Belgium seemed like a precise and specific aim that didn’t require a master plan for the continent.
The government decided it could clear out Belgium and be back home in a week, back home in time for Christmas, back home in time for New year...
We went into World War I as a naval power with little recent experience of fighting warfare on land against an equally advanced enemy. Sea battles against an inferior foe last a day or two, maybe a couple of weeks.
The War dragged on for 4 long years and we lost a million of our best and brightest people for no gain whatsoever. Progressive social changes started going backwards. Long promised reforms and freedoms promised to Ireland were delayed by the war and we lost them. We bankrupted ourselves and started to lose the whole Empire. We even killed Mel Gibson again at the incompetently run campaign at Gallipoli.
France continued Empire building in the Treaty of Versailles, trying to guarantee a permanent superiority over Germany. The UK delegation, “the Heavenly Twins”, bankers who were brought in as “worthy finance experts”, despite advice from Keynes in the Treasury to prioritise making sure post-war Germany was viable and don’t worry about making money, decided it wanted a huge pile of money out of Germany too.
If only people today would learn to ignore bankers and ‘worthy’ figures of high finance and listen to Keynes, maybe we would not have the financial crash, the Greece crisis, or in fact World War II.
Rome 7 - World War II
Between the wars, America had started to make aggressive moves against Britain and its empire, so wasn’t even looking at Nazi Germany. If any threat loomed it was from those evil red communists in Russia.
Britain likewise hardly noticed, struggling to deal with colonial demands for independence.
When the first moves in Hitler’s game started, many assumed it was just a corrective to the Treaty of Versailles. Maybe partly it was, but Hitler had got the taste of momentum and was never going to stop.
Hitler, like those before, wanted his own version of a united Europe. Mussolini even used the Roman symbolism directly.
Hitler called Charles V’s Holy Roman Empire (see above) the First Reich. Bismarck’s Prussian Empire was the Second Reich, and Hitler’s own rise to power was the Third Reich, the third German attempt at a pan-European state (ignoring all the other attempts).
This time, it really could not be ignored. Hitler’s grand vision of a united Europe left no room for anyone else, whether internal minorities such as the Jews, or external powers such as Britain.
Germany was the master race, a white Europe united under one government with white troops wearing even whiter shirts.
Britain stood alone against Hitler!
Erm well no. Not really at all.
Forces that the UK fielded were a multi-racial bunch. As well as my Granddad and other British residents and thousands of Australians and Canadians, we had 2.5 million Indian volunteers, we had a Burma Division, a Fiji Infantry Regiment, the Royal Malay Regiment, the Arab Legion and Africa sent six whole divisions of black African volunteers. It goes on and on.
In the following image, comrades look on as a West African soldier is treated by doctors. Many thousand Africans and a million Indians died for our freedom.

Despite all the injustices, problems, disagreements, desires for independence, etc, when we needed them, the Commonwealth was there for us. We wouldn’t even have a UK if it was not for them.
Oh yeah and even the Americans came. Eventually. Thanks. We love you. God bless America.
The multi-racial international British Commonwealth and America beat the white European master race and their all-white allies because all people are equal, all are valid, and all have something to contribute. You don’t have to live in Europe to be valuable.
In 1972, the UK was still not yet in the EU so our borders will still largely open to the world, as they had been since the days of Queen Anne.
Independent Uganda decided to expel all 50,000 of its citizens from Indian origin. 27,200 of them settled in the UK. It wasn’t all easy, there was a lot of racism from the right and support from the real socialists, but they thrived here and like the Huguenots, they became an essential part of the UK population.
The Socialist worker at the time tried to explain to the British people they had nothing to fear:

It is the racist financial elite and the mainstream media that tries to people of Britain against our cousins in the Commonwealth, and they still do it today.
The Guardian is nice, it has a handy app that means I can read it on the toilet, but it is not a left-wing paper, it is a right-wing mainstream media paper like the rest. This is the age of the Internet, diversify your information.
Rome 10 - The European Union
A factor in the wars between France and Germany is that the bordering areas are rich in natural resources. Sharing them helps to prevent arguments which makes peace. In this context the post-war European Coal and Steel Community makes a lot of sense. But Britain has never dug the Ruhr. It doesn’t mean anything to us.
Brussels is the mid-point between France and Germany, good location for them but it doesn’t mean anything to UK except the site of some stupid unnecessary wars between France and Germany where our grandparents and great-grandparents suffered. We did not need to join the EU to stop us conquering France or Belgium. UK has been finished with that since 1534.
So the fact the symbolism of the EU means more to France and Germany and means little to UK, doesn’t come us much surprise.

The EU used to be like a benign attempt at a Roman Empire, but it has become increasingly hostile to its own people, see what happened in Greece, and it is increasingly out of step with British values, go read about TTIP. Read about the Viking Line labour dispute. The EU has long ceased to be a progressive force, if it ever was.

It has a centralised, proprietary setup where the only people that can influence decisions are yesterday’s multinational corporations. It then puts a phoney parliament on top as a democratic fig leaf. The European ‘Parliament’ has two fancy state of the art buildings that it shuttles between. What it cannot do is make any new laws or repeal any old ones. Only the unelected Commission can write new laws, as for repealing laws, there is not a system for that. What a joke!
In 1999, I was an undergraduate with a giant EU flag on the wall of my dorm. I read all the propaganda, went on all the trips. I wrote essays saying while the EU was currently undemocratic, bad for the environment, and bad for the developing world, it would be fixed soon. It wasn’t. All we had to do was co-operate and wait and it will reform. It didn’t.
I even waited in the Snow in 2002 outside the Bank of Finland to get some of the first Euros. What a mistake the Euro was, it has bankrupted Greece and left many of the young people of Europe without a hope of jobs.
Those who funded the Remain campaign are the same people that caused the financial crisis of 2008: Goldman Sachs, Merrill Lynch and J.P. Morgan. They are not our friends or allies.

Much is made to dismiss left arguments for exit because Nigel Farage wants exit. Whatever one may think of him, he has never held power to hurt anyone and never will have power. Meanwhile, Remain’s George Osborne has had power and used it to take money from disabled people and give it to the same billionaires that are backing remain.

Then we come to Remain’s Tony Blair.
Britain in recent history didn’t start wars or kill people, yay! We had finally learned from our past mistakes. That is until the lying warmonger Tony Blair came along.
My own faith in Britain took a massive nosedive then and probably hasn’t recovered, maybe it never will, it is now the cyber-internationale or nothing.
Blair is responsible for choosing to start a war which has killed up to a million people. I will not stand with him and I will probably not agree with him on anything. When you take the same side as Blair, I see you as a right-wing Blairite, I do have to admit that. You have to to, you are one. It is better to be honest that you are right of me.
I am not a European. I am British and I am a human and like Wilberforce, I believe being a human is the more important fact.
I don’t see the need for any layers in between.
I believe that a Kenyan or an Indian or an Australian or a native American is as equal to a Bulgarian or a Hungarian.
The EU means that someone 1000 miles east of me has equal rights to me in the UK but someone 1000 miles south of me has none. I find that completely arbitrary.
The real truth is that European countries are all white, that is the only unifying factor. That is a racist way to order the world.
There is a lot of middle-class European nationalism, as if it is an acceptable form of nationalism, and an acceptable form of racism. It is not. To me it just seems like the last 2000 years of re-making the Roman Empire.
Moving on from being a little Englander is not be a little European, it is to be a citizen of the whole world.
There is a lot of middle-class sneering at the out campaign, that it is full of racists and not the right kind of educated people in the Remain campaign. A racist with a degree is still a racist. The remain campaign is equally racist. Just one step zoomed out. They are still putting up trade and immigration barriers to everyone who is not in the arbitrary group of 28 majority-white countries that is the EU.
If you don’t have a degree, if you are a normal working person sick of the sneering; I have three degrees, you can imagine one of them is yours. They don’t mean anything here. Your voice is equal to the most loftiest expert. Stick to your beliefs. RMT, ASLEF, BFAWU and other Trade Unions supporting Leave know as much, if not more, than the forces of neo-liberal capitalism.
The fact is the Europeans don’t have the Commonwealth history and the relatively happy race relations we have in the UK. We have a different history. That is fine. Let them get on with their Rome building.
Britain can leave and rejoin our Commonwealth and the rest of the world. If Rome 10 still wants to trade with us afterwards, fine, if not fine. We have a massive balance of trade deficit with them anyway so not having a trade deal would both hurt and help us. For Rome 10, not having a trade deal would only hurt them.
Why do you think we have a massive balance of trade deficit with the EU in the first place?
If you remember, the Commonwealth is a group of ccountries whose citizens had stood up and died for us in the war. Before we joined the EU, we put had trade barriers with to the Commonwealth. We had a complementary relationship, we sold them cars and machines and they sold us food, carpets, clothes, tea and so on.
We used to eat cheap food grown without chemicals in the hot sun in Australia, Africa and India. Now we eat expensive pesticide covered fruit grown in heated greenhouses in the low countries. Next up with the EU’s TTIP, we are going to eat American GMO and hormone treated foods, God help us.
We turned on back on the Commonwealth to join a group of similar economies in Europe. We tried to out German the Germans and failed. Why would Germany need to buy our cars or advanced technology? It can make cars itself and often better.
Putting up trade barriers to complimentary countries was a mistake. We cannot all do the same thing. We cannot all do everything. We all live on one planet and we all do best if we all work together.
The Information Age
After the Scottish and English reformations, we had growing freedom of thought and expression, without which the technological and scientific discoveries of the industrial revolution would not be possible.
The machine, from a simple lever to a super computer, magnifies human activity. We have combine harvesters, medical equipment, airplanes. This magnification in productivity has the potential to bring food, health and wealth to every member of our species.
We also need to think about our planet and the other species we share it with.
In this informational age, the EU has nothing to offer, it just wants to bring in software patents so yesterday’s innovators can have monopoly rent. Where is the European Google? Why is all the innovation happening in America, India and China?
The Neo-liberal sweatshop agenda
So far the fruits of the industrial revolution, and now the information revolution, have not been shared very fairly.
There is this horrible propaganda: “immigrants do the jobs British people are not willing to do”.
Existing residents used to be happy picking vegetables, doing factory work, doing care work. These used to be fairly paid secure jobs. People doing these unskilled jobs could afford to buy a house and all the essentials of life.
They did not suddenly become work shy. What happened is that secure contracts were replaced with insecure agency work with serf-like conditions. Local people cannot afford to take them and still raise their families. If your family is abroad where the living costs are lower, then maybe you can make it work but you are still being exploited.
If it is not good enough for a British person, it is not good enough for an Eastern European. Building our economy on the exploitation of Eastern Europe is no more ethical than building an Empire on the backs of Africans and Indians.
This was a choice, none of this happen by accident, it was designed to happen, and the forces of neo-liberalism are becoming very rich because of it.
The stupid thing is that companies with well paid workers in safe conditions using machines, lose contracts to cowboys hiring mass numbers of workers in unstable situations, both here and abroad. It is a technological de-evolution.
Enter the Matrix
Progress goes backwards but it also goes forwards again. Even if temporarily a sweatshop is cheaper than a machine, we can make more productive machines. If an industrial process makes pollution, we can make cleaner machines.
The future of our species is not about providing low paid insecure work, it is about using technology to automate and make work productive enough that we can give everyone decent and fair conditions.
We need more automation, more machines, and yes more developers writing software to run it all.
In the Terminator movies, the real hero is not the gun toting Sarah Conner, it is Skynet. In the Matrix, the hero is Agent Smith.

I don’t want to make Rome, I want to make the Matrix. I want us to work with the whole world and help give them all food, clean water, healthcare, computers and freedom.
The real conservative forces of high finance, the same guys that run the mainstream media and control the EU, of course want to convince you to remain. For me, it is part of the problem, not the solution.
Maybe we don’t leave this EU this week, I hope we do but the polls are not looking good, people are accepting the Goldman Sach’s funded messages. David Cameron won two referendums already using his anti-progressive project fear. I can believe he can win this one too.
However, we will leave in the end, it is just a matter of time, and we will not be the only ones. Across Europe, people are waking up. We don’t need a centralised proprietary government in Brussels to work together across borders. People are coming up with new models for open source government and distributed co-operation. We have just got to pull the arrow of neo-liberalism out of our eyes.
A spectre is haunting Europe - the spectre of technological utopianism. The idea of socialism has existed for a long time, but only now are we finally getting to a technological level where it can become possible.
Lets make it happen.
| [1] | The realities of our economy is that I must write software in order to eat, therefore this discussion is not as polished as I may like but I thought I would get it out before the vote. |
| [2] | George R. R. Martin’s A Song of Ice and Fire series is based heavily on British History, in his version, the elf-like children of the forest bring down the “Hammer of the Waters”, splitting the known world into two, in a desperate attempt to stall the invading humans. |

I made some software (which will be explained in a future post) and used my trusty Argos third-party PS3 style gamepad to control it.
On the way to open sourcing it, I thought I had better try it with a an official Sony PS3 gamepad, and I could always do with another gamepad for when playing computer with the sprog.
We play a lot of open source games like SuperTuxKart and Frogatto which are two of our favourites. To be honest we play almost every game made available through Debian’s Apt.
So not really thinking too heavily about it, I popped onto a leading auction website, typed in PS3 gamepad, saw that the first result cost less than £13 including postage, and just bought it and moved on. Total time spent was about a minute.
Later I thought it was a bit cheap but ignored the thought on the basis that the PS3 is ten years old and has been long replaced by the PS4. The controller that game was the one above. In the following box.

Initial impressions were that it was a little light and the D-pad was different than I remember. However, it is probably been 5 years since I touched an official PS3 gamepad and maybe they made production improvements to make it lighter or I didn’t really remember right.
However, as soon as I plugged it in, and typed dmesg, the controller itself confessed to its real identity.:
usb 4-2: new full-speed USB device number 24 using uhci_hcd
usb 4-2: New USB device found, idVendor=054c, idProduct=0268
usb 4-2: New USB device strings: Mfr=1, Product=2, SerialNumber=0
usb 4-2: Product: PS(R) Gamepad
usb 4-2: Manufacturer: Gasia Co.,Ltd
input: Gasia Co.,Ltd PS(R) Gamepad as /devices/pci0000:00/0000:00:1d.0/usb4/4-2/4-2:1.0/0003:054C:0268.0010/input/input41
sony 0003:054C:0268.0010: input,hiddev0,hidraw3: USB HID v1.11 Joystick [Gasia Co.,Ltd PS(R) Gamepad] on usb-0000:00:1d.0-2/input0
A Gasia Co.,Ltd PS(R) Gamepad, what is that you may ask? Well so did I. It should look like this:
usb 4-2: New USB device strings: Mfr=1, Product=2, SerialNumber=0
usb 4-2: Product: PLAYSTATION(R)3 Controller
usb 4-2: Manufacturer: Sony
sony 0003:054C:0268.0008: Fixing up Sony Sixaxis report descriptor
input: Sony PLAYSTATION(R)3 Controller as /devices/pci0000:00/0000:00:13.2/usb4/4-2/4-2:1.0/input/input18
sony 0003:054C:0268.0008: input,hiddev0,hidraw0: USB HID v1.11 Joystick [Sony PLAYSTATION(R)3 Controller] on usb-0000:00:13.2-2/input0
The controller was totally fake!
So it didn’t help me generalise my software. Also these controllers contain a Lithium battery so I am not comfortable putting this counterfeit device in my child’s hands. If they are so far beyond the legal system that they do not need to care about the trademarks of Sony, how much do they care about electrical safety? Or chemical safety?
So I emailed my findings to the seller and they gave me an immediate refund and didn’t need to send the controller back. A counterfeiter with great customer service! Bizarre.
It is amazing the level of detail they went to. It is itself an interesting cultural artefact; a Chinese made plastic product pretending to be a different Chinese made plastic product. It is interesting philosophical discussion about if you use the same design, make it in the same place and maybe even use the exact same parts, what does genuine actually mean?
And what the heck is the markup on the official Sony controller if another company can make an almost exact replica for a less than a third of the price?
It is shame that people feel the need to be dishonest. A third party PS3 controller does not need to hide its true nature. I love my Argos one which has some useful extra features.
Surely selling the controller as what it is would be simpler than having to sneak around and recreate accounts constantly on the auction site?
If the manufacturer had said, “this is a PS3 compatible gamepad and it is three times cheaper”, then it could find its own market. While you are at it, put in a higher capacity battery and better bluetooth aerial than Sony’s controller and win on both price and quality.
As for me, I bought an official wired Xbox 360 controller from Argos. I actually prefer the shape ergonomically and it is more reliably detected by Linux and is much cheaper than the PS3 gamepad.
]]>
This has been a very exciting year. I burst out of the academy and started a new company with a couple of other chaps called Rob and Luke.
The idea is write a platform to help generate form-based applications, which could absorb and display business data. We could then in the future add machine learning/artificial intelligence type features, and learn original ideas that have not been apparent without such statistical modelling.
Basically we are trying to make Skynet, the singularity itself, which we call Infomachine. Of course, being a start-up, it might evolve into a different concept involving washing machines or something.

Meanwhile, some customers found their way to us and we have been doing lots of consulting and contract software development. The customers themselves are highly intelligent and beautiful people who have extensive domain knowledge in their own field, and it has been very interesting learning some of this as we write software to make their companies more efficient or expand into new areas.
This all feeds back into the eventual completion of the Infomachine, or not; maybe we will go in a completely different direction, that is the fun part, there are just three of us in a (often virtual) room and we can do whatever the heck we like.
]]>
In this post I thought about the world of cool that lies between high-level languages and C. Thought is too strong, it is more of a seed of a thought that has not germinated yet. This is not a fable with a moral at the end.
When I first came across C#, I thought that is much better than Visual Basic, perhaps Microsoft’s .Net platform could be interesting one day, but not personally having an obvious project to use it in, I put it to one side and have never touched it since.
When Vala was first announced, I thought wow, that is so sexy and I played with it for about a week. Not personally having an obvious project to use it in, I put it to one side and have never touched it since.
I had pretty much the same reaction to Go (aka golang) - wow that’s cool, perhaps not as sexy as Vala but I like the goroutines. I did the trendy web based tour, I installed everything locally and played with the standard library. Then, not personally having an obvious project to use it in, I put it to one side and have never touched it since.
I could go on and on. Whatever piece of tech that comes into (or back into) fashion seems to follow this pattern, Haskell, Erlang, Java, Scala, etc etc. A lot of the developer tools industry and technology media needs something shiny and new to promote this year.
Don’t get me wrong, I love all this stuff, I would love to do projects in different programming languages but obviously, as I have a reputation for writing Python or JavaScript or doing system administration, people hire me to do that and don’t perhaps think of me for other things.
Maybe there is more too it than that, since in whatever I am doing, in my head I seem to think of any algorithm in Python first as executable pseudocode even if it gets typed in using JavaScript or another language.
I had a long stint as an academic, but basically my whole career in software is as a freelancer or contractor. A journeyman who works to live.
Often the customer has an existing project or specific library, toolkit or team which pre-determines the choice of programming language.
Otherwise, my usual process for creating software is to prototype it in a high level language (normally always Python but sometimes JavaScript). 90% of the time, once it works the customer has solved their immediate problem and wants to move their focus onto their next problem, which may not be software and may not involve paying freelance programmers. Sad I know, thanks for all the fish, I am here, like the song says, etc etc :)
When the prototype is working, there is a lot to be done to optimise it and keep it as a Python application, and almost always there is some specific other bottleneck (such as network, database or some industrial requirement) that means that CPU usage is not the problem and so cutting out the Python interpreter wouldn’t actually make much difference in the short and medium time-frames that most companies care about.
Indeed I have seen cases where the customer has gotten someone to rewrite the prototype application in Java, and found that the new version is actually slower. A lot of the heavy duty work in the Python version was actually happening inside a C library that has been highly optimised over the last 30 years; changing the dependency from that to a poorly implemented Java library caused the poor performance.
If we imagine a Python application is like a commissioning a photograph, a C app is commissioning a sculpture. You only do it when you want something to really last or really be the core of something fundamental for your future success.
All the above notwithstanding, the genius of Python’s initial design is that once your application has taken a stable(ish) form, it is normally pretty straightforward to convert the application to C.
Most of the standard library inherits Linux/Unix best practice (and even the same function names) and a lot of the best external libraries in Python are just wrappers around the C equivalents. You always have the fully working Python application to test it against.
It takes a long time yes, going through line by line, but you are not troubling the boundaries of computer science or software engineering as we know it. I actually love those kind of cathartic jobs, but I am a freak.
Apologies if I am stating the bleeding obvious, none of the above text is news to anyone, any Python developer knows the same thing, however it is the foundation for what follows.
So the real reason why I have not personally had an obvious project to use a lot of these fashionable and ‘cool’ languages and toolkits is that they fall in the luke-warm middle ground between the extremely high-level Python (and JS/Ruby/LISP etc) and the low level C language.
For most use cases, all these middle ground languages are slower and less portable than C. If you have decided on a re-implementation, then it takes no longer to rewrite a Python project to C than to Go, Java, C# or whatever, indeed it might often be quicker to C.
I have actually used C hardly at all, far less than I would like to have done, but I have used these middle-ground languages even less. Everything just stays in high level code.
So as I warned, I have no moral for this fable, no conclusion to offer, it is just the beginnings of a thought that ran through my brain, I like to think I will pick up this theme later, but I will probably look back in five years to find I have put it to one side and have never touched it since.
]]>Image credit: Dancer in the Streets by dannyst

This post is about BBDB (Big Brother Database), which is the main contacts application available for Emacs.
Contacts Application for Emacs
BBDB is packaged within distributions, albeit quite old versions of it are packaged within Debian at the time of writing.
Information about BBDB can be found at its Savannah homepage, and most importantly downloads are found here. I wanted the latest version so I downloaded it from there.
The latest versions (that begin with 3, e.g. 3.1.2) require Emacs 23 or 24, an older version of Emacs will require version 2 of BBDB; although it is much nicer for other reasons to use the latest version of Emacs that you can get.
The README gives full instructions to get set up. Basically, like with most other Emacs libraries, you make the library available by editing the ~/.emacs file and using the require function.
(require 'bbdb-loaddefs "/path/to/bbdb/lisp/bbdb-loaddefs.el")
Storage Format
Despite the name ending in DB, contacts are stored in a plain text file at ~/emacs.d/bbdb (where ~ represents the user’s home directory).
It is worth knowing that each line in the file is a contact, which takes the form of a vector, this is a LISP data type similar to a JavaScript Array or Python list (but items are delimited with spaces rather than commas).
If you ever edit the file by hand or with code you write yourself, it is important to keep one item to a line, if a line break gets removed then BBDB will reject the file until you fix it.
Since it is a plain text file, you can do back it up easily, sync it between computers, write scripts that do things to it, track it with git or whatever you can imagine.
Importing Contacts

If you already have a load of contacts somewhere, then the best way to get started is to import them from there. I personally had a load of contacts in Google Contacts that had been built up from my Gmail account and Android phone.
I used a lovely little Python script called charrington which grabbed all the contacts from Google and added them to a bbdb file.
Using BBDB
As always, M is for Meta which means Alt on an IBM-PC style keyboard.
Typing M-x bbdb allows you to search for a contact. So if I search for Elizabeth, I get this contact:
The other commands all start with bbdb- for example, M-x bbdb-create allows you to type in a new record. There is almost a hundred commands, but you do not need to remember them. Using tab completion shows them all, they are also organised in a toolbar menu.
If you have imported lots of contacts from Google Contacts, then sometimes different pieces of information about a person are stored under different names.
One of the most useful things is M-x bbdb-search-duplicates, this allows you to merge contacts together and/or delete duplicate contacts.
Sending Mail
When you have point over a record, pressing m will allow you to compose an email to the person. Emacs then drops you into message mode.
Email in Emacs is another topic entirely, but if you put the following into your ~/.emacs file then you have setup the absolute basics:
(setq user-mail-address "[email protected]"
user-full-name "Your Name")
If you have a mail transport agent or relay (such as mstmp) setup then Emacs can pass the email to whatever is pointed to by /usr/sbin/sendmail or you can use Emacs itself to relay email.
Other features
Pressing simply e edits the current line. ; allows you to write an attached note. If the record has a www field then W displays the web page.
You can even phone your contacts directly from Emacs! Typing M-d will phone the current contact; obviously you need to have a modem or some other kind of phone system setup.
Various mail and news packages for Emacs can make use of your contacts to provide auto-fill functions, e.g. in the To: field of an email.
Image credit: Phone Call 8 by johnberd first contact by momo5

msmtp is yet another Mail Transfer Agent that merely relays the outgoing email message to another (e.g. your ISP’s) SMTP server. There seems to be quite a lot of these, but this one seems to be the most actively maintained - see its homepage on sourceforge for more information and documentation. At time of writing, the last stable release is March 9, 2014 which is very recent.
Other similar ones, such as ssmtp, esmtp and nbsmtp, still seem to work, they are pretty simple programs with few dependencies apart from the C environment which basically never changes anymore and they are recompiled and repackaged regularly by the distributions.
I have a machine running on Debian stable but wanted a newer version of msmtp than is packaged for stable. So I cloned the source code using git and compiled it.
However, after removing the default mail transfer agent (Exim), Debian’s apt command is desperate to re-install it.
So I needed to tell the system that I already have a mail transfer agent. This post explains how I did it. I don’t know if this is the correct ‘modern’ way to do it, but it worked for me, and it is quite interesting because it exposes a little of how Apt works under the hood.
Fortunately, my problem is the use case given in the old Apt Howto under the section called 4.1 How to install locally compiled packages: equivs there is more useful information there.
The package that helps us to circumvent Debian package dependencies is called equivs, so first I needed to install that. sudo apt-get install equivs
sudo apt-get install equivs
Next I ran the following command.
equivs-control msmtp-git
This created a template Debian control file. I gave it a meaningful name, i.e. msmtp installed from git.
I added the following lines:
Package: msmtp-git
Provides: mail-transport-agent
The Provides line is the key, it tells the system that a mail-transport-agent is installed.
Then I created a .deb from this control file.
equivs-build msmtp-git
Lastly I installed the deb:
sudo dpkg --install msmtp-git_1.0_all.deb
Pretty weird but it works.
]]>Image Credit: Atlas - The Titan’s Punishment by IndigoDesigns
In the digital humanities when a scholar wants to transcribe and edit texts such as ancient or medieval manuscripts, that scholar uses her institution’s own systems (for the rest of this post I will call this a ‘site’).
In Birmingham we have the Workspace for collaborative editing that I was the main coder on, this provides editing and analysis facilities for digital text projects hosted or associated with the University of Birmingham in some way. There are several of these kind of sites, maybe even dozens.
Textual Communities is another such site, based at the University of Saskatchewan, wherever that is, however, the difference is that Textual Communities aims to “provide an infrastructure and tools to allow anyone, anywhere, interested in a text to contribute to its study, as part of a community working together.”
Here is a photo of some of the main Textual Communities people:

So as part of the Estoria de Espanna Project, I have been using Textual Communities and integrating it somewhat with some display and analysis tools on a server in Birmingham.
Part of the vision from the Textual Communities people is to build a global editing community, which would imply being an open and distributed system, not being based on one server.
Furthermore, there are performance and reliability drawbacks to relying on a single server in Canada to hold the data and pass it back and forth in real time over HTTP.
So the first immediate approach I have taken is to use database replication.
1. Master/slave model
The immediate steps to make Birmingham back up the Canadian site is a simple and low level approach and it is a master/slave model.
Master = Canadian Server
Slave = Birmingham server
1. Every Hour, the slave server checks that the connecting SSH tunnel is still up, if it is not it re-establishes it. The SSH tunnel can be broken by server reboots or network issues.
2. Every time a write happens on the master server, the slave copies it automatically.
3. The code that builds the edition (the public frontend that is one of the key project outputs) works from the local copy of the database which is far more efficient, and if the master goes down, the data is still available locally.
This takes us 50% of the way but there is a big step missing. You cannot actually write data to the slave without breaking the approach, if master is down, and you start writing in the slave, there is no automatic way to get the changes back.
It also doesn’t scale very easily, adding a new site to the global textual community is a completely manual process. Beyond three or four institutions it would be a serious labour cost in maintaining the whole thing.
So sooner or later, you need to design a high level approach. The rest of this post is what I have been studying and building little test prototypes for.
2. A textual communities distribution system
Caveat emptor: So this the approach I have been working on, it may not be the approach favoured in the end by the Estoria project or Textual Communities.

Versions of data can be written at different sites and shared between them, yet what is considered the ‘approved’ or ‘best’ or ‘current’ version may be different at different sites.
Therefore the key to making textual communities into a distributed system is to separate the sharing of versions from the interpretation of these versions.
Each site must therefore keep an additional file/directory form of the data for use by the distribution system. These are plain-text files that can be easily backed up and easily analysed (a similar format to the existing textual communities API, see below).
The actual textual community software does not have to be run from these files, e.g. the Canadian site which uses MySQL can carry on doing so, but the internal changes to the database are exported in real time to plain text files in the data directory.
Likewise, changes by other sites can then be read into Canadian MySQL database from the data files (which changes are accepted and applied is subject to its merge algorithm, see below).
The data files are organised in a three level directory structure. The naming of the directories can be interpreted in different ways:
According to an SQL database approach:
database_name/table_name/row_id/
Or in a document oriented approach:
database_name/collection/document/
Or in object oriented way:
object_name_space/object_type/object_id/
Inside the lowest level directory are files, each file is a version of the data fragment expressed in (or at least wrapped) in JSON. The system of distribution does not actually care what fields are inside the file.
For example, a transcription of a page in the textual communities API is already expressed in this format with a field called “text” which contains the TEI XML text, as well as other fields (id, user, doc, create_date, commit_date, prev, next).
The first version of this data file would be named like this:
textual_communities/transcripts/1688800/1.json
New versions are written according to a principle called copy-on-write. When a new version is written, the old file is left alone, the new file is called:
textual_communities/transcripts/1688800/2.json
There is also a symbolic link called ‘current’, this points to what is the current canonical version of the data (for this particular site).
Different people at different sites can generate new versions of the file, which are automatically shared using git. However, what ‘current’ points to depends on a site specific algorithm.
The simplest algorithm is to point current at the file with the highest integer in the file name, however, sites with editors and crowd sourcing etc will not do that, current will only be re-pointed when the editor (the scholar) has approved it.
Groups of sites can have the same of or different algorithms, it does not affect the system of distribution.

Since data files are tracked and shared using git, this creates metadata that can be used to power a user-friendly web frontend for editors to see new versions, approve/disapprove them and look at history.
When a new version is approved by the local editor, current is repointed to the new file, if the version is not approved, it is just ignored. Undoing a new version is moving current to the older file, the rejected change is just ignored.
Using plain files and git solves many problems with crowd sourcing and distributed editing without having to write the software ourselves.
When the files are used, e.g. they are loaded into the Canadian site’s MySQL database, the file pointed to by current is uploaded, the other files can be safely ignored.
Git has an event based system known as ‘hooks’. So for example, when a new version of a file is created at a site, various actions can happen, such as notifying the relevant local editors that a newer version is available and can be approved or ignored.
3. Beyond Textual Communities - Digital Editions
While it is somewhat parochial to talk about the project I am working on, others in the global “Textual Communities” may have the same aspirations and problems. Eventually you want to take the live form of the text and turn it into digital editions.
The previous projects I was working on used Python and MongoDB for serverside applications, but increasingly I am using IndexedDB, Javascript and HTML5 to make the local browser do the work and allow the user to continue offline.
These data directories can, more or less, be exposed via the web server to Javascript as is, just with a few bits of censoring any relevant private information. This is several orders of magnitude more efficient than an application server like Django or Ruby on rails serving the data.
I have been working on a B+Tree representation of the Estoria de Espanna project data to provide search and a fast web frontend, these can be read directly from the data files.
A fast web server like Nginx throwing out static files combined with B+tree index for searches is pretty much unbeatable in terms of performance. It is also pretty future proof - stupid lasts longer than clever! The importance of this cannot be overstated in externally funded projects that exist for their period of project funding and then afterwards are maintained on a while-we-can basis.
Also, I am hoping to produce native mobile applications as part of the Estoria project output, compiling an abridged version of the data files directly into the app is far easier and has far better performance than trying to port web application code to a phone by statically linking in a Python interpreter.
4. The End of the Beginning
Somebody might come up with something better and the Textual communities probably have their own strong ideas, but this is where my thoughts and experiments are at now.
{kind=link}
In this post we look at the changes in disk mounting and then look at the udisksctl command which allows you to automount disks from the command line. Feel free to skip past the background info if you just want to learn how to use the command.
Background
In the beginning (Thursday, 1 January 1970?) to add a storage device (such as a hard disk) to a computer was an infrequent affair, and required the machine to be turned off.
So the classic system of disk mounting on a Posix (‘Unix-like’) system was for the system administrator to list all the disks in a plain text file systems table, which on most systems can be found in the file /etc/fstab.
Nowadays servers often have the ability to add and remove disks without turning the machine off. Even in desktop computers, SATA drives have this facility too at least according to the SATA drive - but it depends a lot on the manufacturer of motherboard controller actually following the standard so it is not usually worth the risk.
The main thing that has really brought hotplugging into use is external disks such as USB drives and other trendy connectors that come and (mostly) go such as Firewire, eSata, Thunderbolt, etc.

In the early 2000s, the first attempt to cope with this was called HAL - Hardware Abstraction Layer, which did what it said on the tin, provided a layer between device nodes and the user of the nodes, so storage devices (and other hardware) can be added and removed without rebooting this system and without rewriting the /etc/fstab file.
Then everything gets replaced a dizzying number of times (DeviceKit, devfs, etc) as better approaches are discovered in a fast moving period of hardware development, udev eventually won and was the main thing for the rest of the decade.
When a device is added or removed from the system, the Linux kernel notices and sends out an event. Udev is a daemon that waits around listening for these events and then responding accordingly. udev runs in user space not kernel space which is good for security as you cannot plug in a USB stick and take over the kernel like on some proprietary operating systems.
In 2012, the udev project merged into the systemd project; systemd is the next generation (or current generation for some distributions) system and service manager. Systemd is really cool and is being adopted by most of the major distributions but it is still a year or two away in some cases depending on their release cycles.
Anyway, the point is that if you want to control disks on the command line and you are using the mount command you are 20 years out of date. Enough history, lets get to the flesh.

Command Line Usage
When you hot plug disks in the system, the graphical interface automatically reacts and provides buttons to mount, unmount and so on. However, if you have accessed a machine remotely, or just like to use the command line, then this post will tell you how to use the same automounting approach as the GUI.
For a system controlled by udev (or systemd), one command line tool is called udisks. It has two versions, in the original version 1, the command is udisks, for the second version udisks2, it is udisksctl.
If you don’t have these commands already installed then you will have to install the udisks2 or udisks packages. In the case of the Debian distribution, udisks is in Wheezy and udisks2 is in Jessie. I seem to have both installed for some reason, possibly because I started at Wheezy and upgraded to Jessie.
Anyway, we will look at the newest one, udisksctl.
udisksctl
The main commands follow, there are several more that can be seen with:
udisksctl help
To see a list of disks attached to the system:
udisksctl status
For a very in depth list of disk information:
udisksctl dump
To mount a filesystem:
udisksctl mount -b /dev/sdb1
You don’t need to give a location, it will sort that out automatically for you. On my system it mounts the disk at /media/username/label where username is obviously your username and label is the label of the disk partition, other distributions may deal with it differently.
To unmount a filesystem:
udisksctl unmount -b /dev/sdb1
Note that the command is unmount with an N, not umount like the classic command.
Note that these command names autocomplete which is kinda cool.
udisks
The old udisks command is pretty similar except instead of giving a command name, you give an argument, e.g. to get the full disk information:
udisks --dump
Instead of status, it has –enumerate. This option lists partitions instead of physical disks like in the newer udisksctl.
Go forth and mount
So udisksctl is pretty cool, we can now mount and unmount disks from the command line in the same way as the GUI. Do remember that the disk information from the udisksctl dump command can quite be useful when wanting to know about the disks attached to a system.

Note: everything below refers to the default (missionary position) C implementation of Python.
If you are converting Python code from Python 2 to Python 3, you might notice that the conversion tool transforms any uses of long() into int(). If that confuses you, this post will hopefully make it clear.
Before Python 2.2, there was a clear distinction between two of the Python numerical types, the int type and the Python long type.
Firstly, Python’s int type was implemented as a signed long. So a Python int takes 32 bits of memory, which while not as efficient as some really optimised approach using shorter types, is still very fast indeed.
Secondly, Python’s long type is an integer of unlimited size (well until you run of RAM - which would be an unrealistically massive number not useful for anything).
Python’s long type does not map directly to a C type, it is a custom type implemented in the Python source code somewhere which I guess uses a C struct or whatever. As you might imagine, using the Python long type is significantly more RAM intensive and slower than the Python int type, but in reality it is rarely a problem (see below).
Hans Fangohr did a little performance testing and found that Python’s long type is about three times slower than the Python’s int type.
Unified ints were brought in for Python 2.2. This starts off as a Python int but transforms magically to a Python long if it needs to. Here is how it works in Python 2.2 to 2.7:
>>> import sys
>>> sys.maxsize
9223372036854775807
>>> type(sys.maxsize)
<type 'int'>
>>> sys.maxsize + 1
9223372036854775808L
>>> type(sys.maxsize + 1)
<type 'long'>
>>> long
<type 'long'>
Note that when we add 1 to sys.maxsize, the result has an L suffix to denote it is a Python long and no longer a 32 bit number.
In Python 3, it works in a similar the way, however the fact you are no longer using a 32 bit type is now completely hidden away from the user:
>>> import sys
>>> sys.maxsize
9223372036854775807
>>> type(sys.maxsize)
<class 'int'>
>>> sys.maxsize + 1
9223372036854775808
>>> type(sys.maxsize + 1)
<class 'int'>
>>> long
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'long' is not defined
This time, when we add 1 to sys.maxsize, the result has no L suffix; trying to call the long constructor function causes an exception because it does not exist anymore in Python 3.
Of course, the fun of Python is that being a high level language, we normally don’t really care as long a we get a number; this is it rightly got changed it to be one unified type.
One might design a high performance application not to use the Python long type if it turns out to be a bottleneck. However, normally you would have other bigger insurmountable bottlenecks in your software/hardware/network stack so you don’t care about this.
However, if you are working on a multi-language project, especially if you are using Python alongside a lower level language like C, then it is useful to know what is going on underneath the Python types.
The Python float type is implemented as a C double. This doesn’t change across versions. Several other numeric types are available in Python of course.
So if you see long being converted to int by the 2to3 conversion tool, now you know why.
]]>Image Credit: The Spiderbot by Raikoh
In this post we will example the digital text and how and why it is encoded.
Denarius
Wars are often an unexpected event, and a lot of the major currency developments in the 19th and 20th centuries were due to wars. In the ancient world it was no different. The requirement to quickly gather resources required an efficient form of money.
During the Second Punic War, in 211 BC, Rome brought out the Denarius, which means ‘containing ten’ - because one silver Denarius was worth ten bronze (later copper) Asses.
During the Third Punic war, in 140 BC, Rome decided to go hexadecimal, where one silver-coloured Denarius became worth 16 copper Asses.
The silver-coloured Denarius was considered a day’s wages for a soldier. The gold-coloured Solidus varied in value but eventually stabilised by the 8th century as 12 denarii.
The Romans carried spread currency around and in Britain, the denarius became the penny but was still written as d until 1971 e.g. 5d for 5 pence.
12d made a shilling, which is the Anglo-Saxon term for the Solidus. The shilling was in the 16th century pegged to the value of a cow in Kent market.
Twenty shilling made a pound which was named after the unit of mass, a pound in cash was originally worth the value of a pound weight of silver (which is now about £300).
The pound of a unit of mass is itself Roman of course, from libra, which is why pound is shortened to lb. The pound £ sign was originally an L. 1 lb in mass is 16 ounces.
Part the deal when Britain applied to join the European Economic Community in the 1960s and 1970s, was that we got rid of all these crazy measurements and adopted metric, also known as scientific measurements, which we did eventually, to a certain extent. For example, milk, beer and cider are officially sold in units of 568 mL!
So until recently, the idea of non-base 10 measurements was completely normal.
Binary
George Boole was a theologian who was also one of the greatest mathematicians of the 19th Century.Boole understood mathematics and religion as intertwined. George Boole believed that studying mathematics would help reveal a new understanding of God.

More on George Boole: http://zeth.net/archive/2007/07/19/what-is-truth-part-3-all-you-need-is-one-and-zero/
The core idea that all knowledge and thought could be reduced to two factors nothing (0) and God (1), had long been discussed, for example by the the Jesuit Gottfried Leibniz writing in the 17th Century. However, Boole had the mathematical knowledge to take the idea and build a complete system of logic around it.

Everything is either True (God - 1) or False (nothing - 0):
1 or 0 == 1
0 or 1 == 1
1 or 1 == 0
0 or 0 == 0
1 and 1 == 1
0 and 0 == 0
1 and 0 == 0
0 and 1 == 0
not 0 == 1
not 1 == 0
Everything that is not God is nothingness, everything that is something is God. God fills the nothingness but the nothingness cannot conquer God.
Any number can be represented by any sequence of bits. A bit is 0 or a 1.
| Binary | Decimal |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 10 | 2 |
| 11 | 3 |
| 100 | 4 |
| 101 | 5 |
| 110 | 6 |
| 111 | 7 |
| 1000 | 8 |
| 1001 | 9 |
| 1010 | 10 |
| 1011 | 11 |
| 1100 | 12 |
| 1101 | 13 |
| 1110 | 14 |
| 1111 | 15 |
| 10000 | 16 |
Traditionally, eight bits was called a byte (more correctly it is an octet). Four bits is a nibble.
A computer processor has lots of microscopic transistors. The CPU in my laptop (the Intel Ivy Bridge) has 1.4 billion of them. Each transistor is like a switch with an on and off state.
Hexadecimal
Binary is very low level. The first level of abstraction over binary is called hexadecimal.
In previous lecture, we looked at how and when and where computing was developed. These early computer developers choose the most efficient representation. As we mentioned earlier, until recently non-base 10 measurements were completely normal.
Hexadecimal (‘hex’ for short) is counting in base 16, here is the table from above with hex as well:
| Binary | Hex | Decimal |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 10 | 2 | 2 |
| 11 | 3 | 3 |
| 100 | 4 | 4 |
| 101 | 5 | 5 |
| 110 | 6 | 6 |
| 111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | a | 10 |
| 1011 | b | 11 |
| 1100 | c | 12 |
| 1101 | d | 13 |
| 1110 | e | 14 |
| 1111 | f | 15 |
| 10000 | 10 | 16 |
Now it is easy to convert any binary number to hex. You just split it up into nibbles from the right.
So this number:
11111011110
Split up is:
0111 1101 1110
7 d e
So in hex it is 7de.
What number is it in decimal? Well that is more complicated. Going from binary to decimal requires you to split the binary number up into parts:
10000000000 1024
1000000000 512
100000000 256
10000000 128
1000000 64
10000 16
1000 8
100 4
10 2
1024 + 512 + 256 + 128 + 64 + 16 + 8 + 4 + 2 = ?
So data is electrical impulses in a transistor, which represent 1 and 0, which are then hexadecimal numbers.
Now we have numbers, we can now encode characters. Each character is given a hex number.
So 41 in hex (which is 65 in decimal) is “latin capital letter A”.
There are different encodings (mapping between numbers and characters) but the only one that really matters in 2014 is called UTF-8 commonly called Unicode (although there are other forms of Unicode which did not win).
UTF-8 has room for 1,112,064 different characters and symbols which aim to represent all of the world’s languages.
The first 128 characters are carried over from an older standard called ASCII. The first 32 of these are historic control characters for controlling printers and teletype devices (remember those from a previous lecture?).
20 in hex (so 32 in decimal) is the empty space, then we get punctuation, then we get the numbers and so more punctuation etc then the letters in upper case then some more symbols then the letters in lower case etc.
This gets us to 7E (126) which is ~, and we have all of the English keyboard covered. The next 129 characters are Western European languages (German etc) and then it carries on after that through all the world’s letters and symbols.
Including some really fun stuff added to give compatibility with Japanese mobile phones:
http://www.fileformat.info/info/unicode/char/1f4a9/index.htm http://www.fileformat.info/info/unicode/char/1f302/index.htm http://www.fileformat.info/info/unicode/block/miscellaneous_symbols_and_pictographs/images.htm http://en.wikipedia.org/wiki/Emoji
So a digital text is a series of these hexadecimal numbers representing characters and symbols including spaces (20 in hex/32 in decimal) and control codes such as line breaks (0A in hex, 10 in decimal) and so on.
Here is a nice chart version of the first 127 (ASCII) characters: http://web.cs.mun.ca/~michael/c/ascii-table.html
So you can decode these characters (with some spaces added to make it simpler):
41 6e 64 20 74 68 65 72 65 66 6f 72 65 20 6e 65 76 65 72 20 73 65 6e 64 20 74 6f 20 6b 6e 6f 77 20 66 6f 72 20 77 68 6f 6d 20 74 68 65 20 62 65 6c 6c 20 74 6f 6c 6c 73 3b 20 49 74 20 74 6f 6c 6c 73 20 66 6f 72 20 74 68 65 65 2e
To make it clear that something is a hex value, it is often prefixed with 0x or x or U+.
This is as good as it far as it goes. But to make practical use of the data, just loads of text doesn’t help that much.
If we want to make a digital representation of a humanities artefact like a manuscript, we need to use a file format. Otherwise the digital text is of limited use for other scholars and software.
Why not use a word processor?
A word processor is an approximation of a late 19th century typewriter. A word processor will not help in transcribing this:

Let alone this:

What about this:

How about this:

In the 1980s and onwards, a group of humanities scholars created the TEI, which is a set of guidelines for digitally representing humanities data:
These Guidelines apply to texts in any natural language, of any date, in any literary genre or text type, without restriction on form or content.
The guidelines can be found online here:
http://www.tei-c.org/release/doc/tei-p5-doc/en/html/
The TEI was initially SGML based then became XML based. What this means is that the text of the artefact is typed up, and meaning and extra information is inserted into the text using angle brackets.
An example of a text encoded using the TEI format: http://epapers.bham.ac.uk/718/1/47.xml
So in this simple line here:
<w n="6">testimonium</w>
The element <w> which means word, has an attribute n with value 6 which quite obviously tells us that it is word number 6. The text of the word then follows, and then the word ends with a closing tag: </w>
As explained in the preface to the TEI guidelines, part of the reason for them was to enable sharing of data and a new generation of shared TEI-supporting software to emerge.
Sadly that never really happened. The problem with the TEI is that it is a huge standard that doesn’t really simplify the problem space in any way. There are hundreds of available elements and every author of a TEI document uses their own subset it in his/her own way.
Churchill famously said that “Democracy is the worst form of government, except for all those other forms that have been tried from time to time.”
TEI is the worst form of encoding, except for all the other forms that have been tried from time to time.
Wizard of OZ
https://github.com/TEI-examples/tei-examples/blob/master/nypl.org/WizardOfOz.xml
JSON
Current interest is in storing text in JSON. Here is a really simple example:
http://zeth.net/examples/example.json
It shows a single verse.
Plain Text formats
Collating
Collating is comparing texts together. Show examples.
I thought it might be useful to give a non-digital example first. We will see whether it really helps or not!
Trams: a case study in technology
In 1700, what we now call South Birmingham was a patchwork of small subsistence tenant farms, but as people left the land to work in factories and other industrial jobs, these farms gradually became larger.
Here is a map of Birmingham in 1831, as you can see South Birmingham does not really exist yet. The built up areas are what is now known as the city centre:

One of these larger farms was called the Grange Estate, in the following image, Isaac Bate and his family pose outside the farmhouse in 1876:

At the turn of the 20th Century, there was a massive housing boom and the Grange Estate was bought in 1895 and zoned for housing and roads.

It is like Sim-City, everything needed for the good life is provided, including shops and the important combination of a church and a brewery.
Victorian industrial workers would walk or cycle along quiet tree-lined avenues and then take the tram and train for longer distance travelling.
So far so good. You will notice there is no car parks, no off street parking, no garages. The total number of cars in the world was at this point was approximately 25, most of which were Benz hand made cars in Germany.
However, after the war, the brave new world required that the trees, train station and tramlines were all removed to make more space for the motorcar.

The Grange Estate is now overflowing with cars, and the Alcester Road is a traffic jam for much of the day. Traffic accidents are the leading cause of death for children and Birmingham is one of the most obese cities in Europe.
Car ownership in Birmingham peaked at 50% of households, one of the highest rates of car ownership for a large city. There is not, and never will be, enough space for everyone to own a car in dense urban areas like Birmingham.
Cars socially exclude people who do not own them, and are dangerous to people walking and cycling, and prevent community building as you cannot talk to other residents while stuck in a small metal box.
There are currently 380,000 cars in Birmingham (8000 are added every year). As the population of Birmingham is predicted to continue growing, the car is becoming increasingly unsustainable. The council have produced a plan:

You guessed it, the plan is to reopen the train stations and put the trams back. Getting us precisely back to where we were in 1896.
The new Birmingham trams have a maximum capacity of 210. Cars in Birmingham have an average occupancy rate of 1.2.
A car driven for an hour every day, spends 4% of its time in use, 96% of its time rusting and getting in the way.
Cars are overproduced and inefficiency used. However, this overproduction has provided large numbers of good jobs - 145,000 in the UK alone currently work in the automotive industry.
If everyone moves to trains, trams and bikes, where do the jobs come from?
If Birmingham gets its comprehensive tram network, it needs just 120 tram sets to provide transport for the whole city (service every 6 minutes each way).
What does Birmingham’s 60 year love affair with the car tell us about technology?
- Increased technological efficiency destroys jobs (while creating others).
- Sometimes you have to go “back to the future”
- Not all new technologies are necessarily a good idea
- Technology is never un-invented, everything survives somewhere but the rate of growth or decline is the important thing to notice.
The history of the computer is much like the history of the tram.
The real history of computing (short version)

The first programmable object is the Jacquard Loom in 1801, it used punch cards which allowed different weaving patterns.

The digital age almost begins in 1843, when Lady Ada Lovelace (the daughter of poet Lord Byron) wrote the first computer programme, algorithm for Charles Babbage Analytical Engine to compute Bernoulli numbers.

The programme was written as part of a set of examples of what could be run on Charles Babbage’s computer the Analytical Engine. Sadly, the British government decided to cancel his research funding so this machine was never finished, but it would have been the first general purpose digital computer.
Here is his earlier machine called the difference engine:

The digital age tries to begin again in 1936 when Alan Turing explains in a seminar paper that any real-world general-purpose computer or computer language can approximately simulate any other real-world general-purpose computer or computer language, i.e. it is “Turing complete”.

Turing went on to create this, the Bombe, a machine designed to decipher encrypted German messages during World War II.

The successor was called Colossus, and is starting to be a recognisable computer.

Alan Turing was not appreciated during his lifetime, to put it lightly. However, now he is a man of many memorials, including these:



After that we have the first non-military computer, the Manchester Mark I in 1949, and pretty much from here the digital age has begun.

The next image shows the Atlas, also at the University of Manchester, the world’s most powerful computer in 1962. It had more computer capacity than the rest of the United Kingdom put together.

This is the 1970 PDP-11 operated here by Ken Thompson and Dennis Ritchie.

Thompson is sitting at a teletype terminal. Where you code into the keyboard and the computer responds by printing out the result.

Shortly afterwards, video terminals were invented. Such as this one:

It may look like a computer, but it is actually just a screen and a keyboard, all the processing happens in the mainframe computer elsewhere.
These type of computers can and normally did had multiple terminals, sometimes in other rooms or other buildings.

In the 1970s, it was called time-sharing. Hundreds or thousands of terminals could share the same mainframe - which would be maintained and updated by specialists.
I love this next photo, the guy in the front looks like he has the universal programmer’s tense expression, i.e. ‘Why the heck is this not working now?’.

These mainframes ran an operating system called Unix started by Thompson and Ritchie. The different terminal users could communicate with each other and collaborate.
The terminals got smarter over time, and even had graphical front ends that looked something like this:

This was the start of the modern era of computing. Many programs that were written in the 1970s are maintained today. There is a continuous thread that runs from Lovelace and Babbage, through Turing to the real beginning of the digital age in the 1970s.
So far so good. This is our tram. Next, comes the car, or indeed two of them.
1. Personal computers
Here is an early attempt from 1969 to market a home computer.

This particular model was a commercial failure.
When the PC came out, such this example from 1981, compared to the Unix systems of the 1970s and 1980s, they were giant step backwards.

No networking, a single process at once, focused on really dull office tasks like typing a letter. The biggest problem looking back was the software.
2. The rise of proprietary software
Until this point, the source code of all programs had been shared among the largely academic computing world. Everyone could study and improve computer programs and share those improvements back to the community.
With the new idea of proprietary software or closed source software, you don’t legally own the software anymore, you have merely licensed the right to use it under certain conditions.

The source of the software is not shared, you just have compiled (unreadable) copy of it. There can now be a difference on what you think the software does (something useful) and what it actually does e.g. spy on you.
When you understand this point, you suddenly a realise it is a bad idea to licence or use any software that cannot be publicly peer reviewed and fixed.
Proprietary software comes with multiple pages of legalese and asks you to tick that you not only read it but also understand it. You have to lie in order to start it, and goes downhill from there.
The Snowden revelations printed in the Guardian have confirmed what we already knew, that Microsoft software has built-in backdoors for the NSA to spy on its users. Even scarier is that secret backdoors created for Microsoft and the NSA could also be exploited by criminals.
Proprietary software, especially in the form of Microsoft Windows, is a temporary aberration in the history of the digital. In 50 years time, Microsoft Windows will be considered as important as this device:

So lets get back to the trams. There were two massive and related developments which happened almost in the background, but would come to dominate the digital world.
The rise of free/open source software
In 1983, a famous programmer in MIT called Richard Stallman began the ‘Free Software’ movement. As well as being a well known software developer (he invented the concept of a live real time text editor and started the most widely used compiler today - GCC), he best known as a digital philosopher.

Stallman argued that software developers had a moral, ethical and political duty to enable co-operation and prevent restrictions on the ability of users to study, examine, peer review, modify and share software. He argued that proprietary software was anti-social, corrupt and ultimately self-defeating.
It is important to understand the difference between the terms ‘commercial’ and ‘proprietary’. Software can be ‘commercial’ - i.e. made by a company for profit, with or without being proprietary. Likewise a proprietary program may be made available at cost or at no cost.
He illustrates the concept by comparing ‘a free beer’ with ‘free speech’.
Eric Raymond and Bruce Perens created a later related concept called ‘open source’, which emphases the practical aspects rather than the political and ethical ones. For example, the vast majority of software is not created for sale in packaged boxes but is created use within companies and institutions where software is not their primary purpose. So if this software is shared and improved in a community, it gives added value to those who engage in it.
Almost every major software development of the 1990s and 21st century has happened within the Free Software/Open Source world including Linux and Android.
Most importantly, the most famous piece of free/open source software of them all, the World Wide Web.
The World Wide Web
In the early 1990s, the best designed and most powerful information protocol was called Gopher. However, despite its technical strengths, Gopher eventually lost out because the copyright owner, the University of Minnesota, wanted to sell it as proprietary software.
And finally a Brit again!

Tim Berners-Lee created World Wide Web, which while technically inferior to Gopher, was free software. Anyone could develop a server or a client without having to ask or pay anyone for permission. When WWW became widely shared in 1993, proprietary Gopher was toast. Gopher was eventually re-licensed as free software in 2000, but it was too late, WWW had taken over everything.
Finally, desktop computers had similar networking capabilities to 1970s mainframes. While they are a lot of people still using Windows, these are merely like the 1970s dumb terminals, 83% of web servers are running free software. Now with Apple OS X (based on FreeBSD Unix-like system), Linux desktops like Ubuntu and the rise of Android based phones and tablet (Android is based on the free software operating system Linux), almost everyone is running a system which is based on the 1970s Unix. The 20 years of the Windows aberration is coming to a close.
Go Linux, go WWW, go Trams, go bikes!
Academia and Open Source Software
Most UK and EU funding bodies now require that any software produced in a research project is released as open source software. Software developers within the academy, especially those in the humanities, are unlikely to be allowed to large pay licensing fees and are expected to use open source tools wherever possible.
Any project that uses the digital is likely to involve some open source software.
Beyond Open Source
The WWW has enabled collaboration in many areas, not just software. Principles and ideas from open source have been applied to other fields.
- Freedom of Information - providing open access to government documents through the Web
- Open Access - unrestricted access via the Web to peer-reviewed journal articles and primary data.
- Crowd sourcing - creating content by soliciting contributions from online communities - Wikipedia being a prominent example
- Crowd funding - funding projects through soliciting contributions from web users - e.g. Kickstarter
Digital Conduct
Collaborative and creative online communities are self-selecting. People form communities to create something, should they also be responsible for social justice?
Should these collaborative communities enabled by the web and by free/open principles have standards of behaviour, if so what should they be and who polices them?
Increasingly these creative communities have published codes of conduct, especially regarding communication and discrimination.
Developing-world criticisms: does attempting to regulate conduct in digital creative communities risk the danger of western (especially US west-coast) cultural imperialism? How do diversity and social policies relate to freedom of speech?
Does forcing participants to use real names instead of pseudonyms cause problems for those with fear of harassment?
How should gender be dealt with in largely male dominated online communities? Are those who run these communities responsible for addressing gender imbalances?
Communities that work primarily online but have conferences or social meetings pose particular issues in terms of harassment/unwanted attention. E.g. conferences with male to female ratios of 10 to 1 are not uncommon.
Some further reading
Karen Sandler, 2012 Keynote, (first 25 mins about hacking the software on her defibrillator), http://www.youtube.com/watch?v=5XDTQLa3NjE
Happy Hacking, The Keiser Report, Russia Today, 2012 (start at 12m) http://youtu.be/3o82P4V1vu0?t=12m9s
The Zen of Python, Tim Peters, 2004 http://www.python.org/dev/peps/pep-0020/
Free Software, Free Society: Selected Essays of Richard M. Stallman, 2002 http://www.gnu.org/philosophy/fsfs/rms-essays.pdf
The Cathedral and the Bazaar, Eric Raymond 2002 http://www.unterstein.net/su/docs/CathBaz.pdf
Revolution OS (2001), http://www.youtube.com/watch?v=CjaC8Pq9-V0
Biculturalism, Joel Spolsky, 2003 http://www.joelonsoftware.com/articles/Biculturalism.html
The Code Of Conduct, Jesse Noller, 2012 http://jessenoller.com/blog/2012/12/7/the-code-of-conduct
Geek Feminism: Timeline_of_incidents http://geekfeminism.wikia.com/wiki/Timeline_of_incidents
Donna Haraway, “A Cyborg Manifesto: Science, Technology, and Socialist-Feminism in the Late Twentieth Century,” in Simians, Cyborgs and Women: The Reinvention of Nature (New York; Routledge, 1991), pp.149-181. http://www.egs.edu/faculty/donna-haraway/articles/donna-haraway-a-cyborg-manifesto/

As talked about previously, my main computers currently have the Crunchbang Linux distribution, which is a version of Debian GNU/Linux using the Openbox window manager.
These tips might also be useful for some other Debian or Ubuntu based systems.
Setting the keymap for an Apple keyboard

While laptops might need flat keys for portability (though I might argue the point), I hate typing on them. I like full-sized keys, not flaccid little flat ones.
I once bought an Apple Mac G4, I don’t use it anymore but I still use the keyboard I bought for it. Using Linux, it is not too much of a problem just to use the IBM layout without (i.e. remembering that the double quote mark is above the 2 key for example) but it is worth setting it properly in case someone else needs to use my computer.
I also have an Apple Macbook Pro laptop for work reasons which also has the same key layout.
Anyway, I edited the file called /etc/default/keyboard and set the following option:
XKBVARIANT="mac"
I am in Great Britain, so I also need to be sure that the following option is set:
XKBLAYOUT=”gb”
Maybe there was a way to change this using a graphical tool, but this way worked.
Creating screen layouts with ARandR
ARandR Screen Layout Editor is a wonderful tool for setting up your monitors. You can drag them around, change the resolution and rotate them in order to create your perfect screen layout.
To save the configuration, click on ‘Layout’ then ‘Save As’ to save a particular configuration.
You can reload this configuration within the program, but the configuration file is itself a simple shell script (which calls xrandr with arguments representing what you have picked in the GUI).
So to automatically configure your screen layout when the graphical session first starts, you can append the script to the file:
~/.config/openbox/autostart
The fact that a configuration is just a shell script means you can easily have multiple layouts for different situations, and either call them yourself on the command line, assign desktop shortcuts or use other tools to call them, e.g. you can use cron to change the screen configuration at a certain time or write an upstart/systemd script to execute it based on some system event etc.
Dealing with not-found commands

When using the command line in Ubuntu, if you try to call a command/program that has not been installed, it says something like:
The program 'tuxpaint' is currently not installed. You can install it by typing:
sudo apt-get install tuxpaint
Here is a more complicated example:
The program 'a2ensite' is currently not installed. You can install it by typing:
sudo apt-get install apache2.2-common
What actually happens here is a Python script appropriately named command-not-found is called which then looks up what package is needed to run the program.
If you want the same behaviour on Crunchbang, just do:
sudo apt-get install command-not-found
The problem with this utility on older hardware is when you accidentally make a typo that is actually a valid command somewhere, you get a second or so delay while it searches Apt’s cache, which could get annoying quite quickly.
If you want to search for a particular package, you can just use the pre-installed apt-cache command, e.g.:
sudo apt-cache search tuxpaint
All the packages to do with tuxpaint are listed in the terminal. However, this does not go down to the file level like command-not-found does. For example, the other example of a2ensite finds nothing:
sudo apt-cache search a2ensite
I don’t know a way of searching for a package by command using the stock Crunchbang install. However, you can install the apt-file package, which allows searches like:
apt-file search filename
8Y3U5AJRHKZ2
So I want to test my web application using multiple versions of Firefox, especially the latest version, but I do not want to mess with my default system version (which is in fact Iceweasel :).
You can make this as over-complicated as you like. The simple way is to ignore apt and your system packaging system and run the test browser completely in user space.
The downside of this is that you will not get automatic security updates, so you have to keep an eye yourself for them and download new versions yourself. On the bright side, the browser is running as an unprivileged user and you are only testing your own site.
So you just download the archive from Mozilla. So I am using 64 bit Linux and I speak British English, so I used the following URL:
http://ftp.mozilla.org/pub/mozilla.org/firefox/releases/latest/linux-x86_64/en-GB/
You can edit the URL as appropriate and then unpack it e.g.:
tar jxf firefox*.tar.bz2
Inside the new firefox directory there is an executable named, somewhat unsurprisingly, firefox, call it in the following way:
./firefox -no-remote -P
This will pop up a little dialogue that allows you to choose the user profile, so create a new one:
You can see I have created a profile called Firefox26. In this way, the new Firefox version will not mess with the main system version. Click ‘Start Firefox’ to launch it. Having a new profile for each test version will keep things both sane and nicely decoupled.
]]>Python is available pre-built for more or less every platform and if you are using Linux or Mac then you have it already. If you don’t know why would you want to build Python from source, then this post is probably not for you.
I wanted to test things on a newer version of Python than is currently available in Debian stable. There are also things I want to improve in the standard library, but sadly I do not have time for that at the present moment - but a man is allowed to dream.
Building Python is explained in the Python Developer’s Guide. This post is a commentary on that, and I am assuming you are using a Debian or Ubuntu based operating system on your computer.
To start with you need the Mercurial source control management tool, commonly known as hg. If you don’t have it, you can get it with the following command:
sudo apt-get install mercurial
Now you need to get the source code of Python, as the developer guide says:
hg clone http://hg.python.org/cpython
You will get output like this:
destination directory: cpython
requesting all changes
adding changesets
Now you have to wait for a little bit; obviously there has been quite a lot of changes since Python began in 1989, so this may take ten minutes (depending on the speed of your computer). There is no progress bar or anything, so you have to just have faith that something is happening. Eventually, I ended up with 301 M in my new cpython directory.
While that is working, open a new terminal tab and start installing the dependencies. As the guide points out, the following gives the minimum required:
sudo apt-get build-dep python3
Several modules in the standard library depend on optional dependencies, to get them all you can do this:
sudo apt-get install libreadline6-dev libsqlite3-dev liblzma-dev libbz2-dev tk8.5-dev blt-dev libgdbm-dev libssl-dev libncurses5-dev
Feel free to leave out the ones you know you are not interested in e.g. a server will not need support for GUIs, so leave out tk8.5-dev and blt-dev in that case.
A slightly obvious point, but worth pointing out, is that some of these packages have version numbers in. If your distribution has newer packages than mine, especially if you are reading this post years after I wrote it, then this command might give errors. In that case, first try increasing the numbers.
Now we are ready to go back to the developer guide:
cd cpython
./configure --with-pydebug
make -s -j2
For completeness, I will just point out that -s is for silent and -j2 allows make to use two parallel ‘jobs’ which then invoke the compiler i.e. gcc (for portability reasons make does not use threads or processes but has its own internal jobserver), you can increase the number 2 but compiling Python is pretty quick (especially compared to the earlier steps), around half of cpython is actually written in Python anyway.
]]>I seem to have become the Littlest Hobo of Linux distributions. I still like Lubuntu, which is perhaps the best known of half a dozen configured distribution disk images based on the fast and efficient LXDE.
However, I accidentally selected an option in the login manager of Lubuntu that made my computer boot into plain Openbox, and I was hooked.
Then in May 2003, I noticed the release announcement of CrunchBang 11 “Waldorf” (which coincided with Debian 7 “Wheezy”) and installed it onto an old machine.

CrunchBang Linux. is even more minimal than Lubuntu, using the Openbox window manager, like Lubuntu does, however Crunchbang does not put any desktop environment on top.
I initially just installed it for research purposes, I wanted to learn what an Openbox distribution looks like when properly configured. I thought I was just picking up ideas that I would be able to bring back to my Lubuntu computer. (It turns out that Crunchbang is pretty much the only Openbox distribution.)
The almost completely empty grey screen felt a bit depressing at first but it subconsciously grew on me; when you have all your applications open, the theme is a tasteful yet minimalist frame, the OS completely gets out of the way.
The key combination Super and Space (Super is also known as Command on the Apple Mac or the Windows key on Microsoft) brings up the main menu wherever the mouse cursor is (you can also use right click). This is especially beautiful on multiple monitors as you do not need to move your focus to the bottom corner of the left most monitor.

The level of configuration and integration is really quite stunning for such a small team. However, once up and running, you are basically just running Debian. Apart from a few packages like the themes as so on, everything comes straight from the Debian stable repositories. Indeed Crunchbang might as well just be one of the default Debian disk images.
After using some form of Ubuntu or other for the last seven years or so, I was initially a bit hesitant to install a Debian based system on my desktop. However, I need not have worried, the difference between Debian and Ubuntu is rather marginal and certainly far less than my previous jumps from Slackware to Redhat to Gentoo to Ubuntu.
]]>Lubuntu is a version of Ubuntu with the LXDE desktop instead of Unity. I am not a Unity hater, I actually like Unity a lot. I just like LXDE more.
LXDE is a desktop focused on performance and keeping out of your way. It is based on GTK+, so in practice it is similar to GNOME or Unity.
I have to admit it is not yet as polished as those other desktop environments, especially the preferences tools are not as consistent and simple as the ones in normal Unity. Since I am the kind of person who ignores the desktop tools anyway and installs my own choice of programs, it doesn’t really matter a great deal.
The LXDE and Lubuntu projects are relatively new and have quite small teams (after all, the more well known GNOME project started in 1997).
If you are interested in writing software for the open source desktop, there seems to be a lot of niches unfilled, a lot more opportunities to make an impact in this kind of project.
I often read articles on the web recommending LXDE for old computers, where is does work much better than more hungrier desktops. Indeed I started using Lubuntu because a computer was struggling with Unity, so I replaced it with Lubuntu and it became a lot more responsive.
However, the same theory applies to new computers too, why waste RAM and processor cycles on stuff you are not even using 99% of the time?
The RAM and processor are there to run the programs I want. The desktop environment, and the operating system in general, should use as little resources as possible.
Currently, Lubuntu has now become the main operating system I use on almost all my computers. I have not tried other LXDE desktops, such as those from Debian or Fedora, I would be very interested in how they compare to Lubuntu.
]]>Yesterday I installed Lubuntu on the Macbook Pro Retina 13 inch. (MacBookPro10,2). I am going to talk about it here. It will be useful for installing normal Ubuntu, or other Linux based distribution on this model of laptop. At the level of hardware support, all flavours of Ubuntu are the same, regardless of the desktop environment.
There are some dire posts on the web saying installing Ubuntu on this machine is impossible. This is not true.
Installing on Macbook Pros are always a bit more involved than PC laptops, partly because Apple is very innovative and always uses the most up to date hardware, it doesn’t seem to care much about compatibility with other hardware or even with its own older products. However, it also does not share its plans or co-operate much, so by the time that the support has got down to the Linux distributions, Apple has completely changed its product line again for the next Christmas.
I found this laptop much easier actually than when my last Macbook Pro come out a couple of years ago, that was a bit of a disaster until support made it into the distributions. I have been using Linux since the late 1990s so I remember some really difficult installs.
Of course it is all relative, it is not as easy as building a desktop of extremely Linux compatible parts (e.g. Intel everything). In that kind of situation, you can put a kettle on, put in the Ubuntu CD and it is finished before you can make a cup of tea. Intel seems to make sure its hardware is supported in Linux before it is released.
If you want that kind of install then, yes, you are out of luck, get a different laptop, maybe one with Linux pre-installed.
Here we are talking more like two hours or so for the install - or longer if you write lots of crap into your blog :)
For this laptop, the main problem is not the install, it is that the desktop environments are not yet geared up for such a high resolution, more on this topic later.
USB Boot
The first hurdle is to make a bootable USB stick. This model of Macbook Pro does not have a DVD drive. Therefore, making a bootable USB stick or bootable USB drive is next easiest thing. I tried two different approaches.
The first and simplest approach is to use the usb-creator-gtk application on an existing Linux system. This is a graphical tool that takes an ISO image which you download from the web (e.g. from the Lubuntu or Ubuntu websites)
The Macbook Pro seemed to be a bit fussy and hard to please regarding which USB sticks it agreed to boot. Best to gather all the ones you own and find one it likes. Before I did my final install, I played about with various distributions on various sticks. I did not notice any particular pattern or reason why some were rejected.
The other approach is to make the bootable USB stick on Mac OS X. This later approach requires a bit more typing but the Mac seems less likely to reject a USB stick it has formatted itself. The Macbook Pro did not refuse to boot any USB sticks using this method, however I did not do a scientific test so it might have just been luck.
Among other things, I tried both Lubuntu 12.10 and the daily build of the forthcoming Lubuntu 13.04. They seemed pretty identical, but it is still a long way until 13.04 is released.
As explained somewhere on this page, the process started with converting the Lubuntu iso into a disk image. I opened a Terminal on OS X (by clicking on the Finder then Applications then Utilities then Terminal), and then performed conversion using the hdiutil command. In my case:
hdiutil convert -format UDRW -o converted-ubuntu.dmg lubuntu-12.10-desktop-amd64+mac.iso
Then I had to use the Disk Utility to re-partition the USB stick to use the horrid Mac OS Extended format. Once I had done that, I used the dd command to copy the disk image to the USB stick:
sudo dd if=ubuntu.img.dmg of=/dev/disk1 bs=1m
That takes quite some time. Check out the article on warp1337 for much fuller instructions.
A note on Mac OS X’s toy file system
I don’t know if they have fixed it now, but in my previous experience, I have found that Mac OS X and its Mac OS Extended format does not defragment itself very well, especially compared to ext4. So after you have run OS X for a long time, the partition will be so fragmented that disk utility will refuse to reduce the size of the OS X partition. In this case the only solution is to reformat the partition and reinstall OS X before you try to install Linux.
If you are buying a Mac with the aim of installing Linux, then repartition the drive as soon as you can. If you want to delay installing Linux for some reason then keep it as FAT or some other generic format (you can get Mac OS X applications that give ext support). If you make it a Mac OS X extended format partition then OS X might start storing files there and will then break or moan once you replace the partition with ext4 or whatever.
Resize Mac Partitions
Now we have to make some space for Linux.
In previous versions of Mac OS X, the utility called “Boot Camp Assistant” would do a lot of the work here, since setting up a partition for Windows would work nicely for Linux too. In OS X 10.8, it wants a Windows DVD to be put in the non-existent DVD drive before it does any work. However, one useful thing Boot Camp Assistant still does is recommend how small you can make the OS X partition, which in my case was 29 GB. So in Boot Camp Assistant, pull the slider around to see what is recommended.
So we need to shrink the Mac OS X partition it and add a new FAT partition, which we will set aside for Linux, this is then reformatted as part of the Linux install. Don’t worry about giving it a swap partition, you can live without it or use a swap file which works just as well.
[Now if like me, you have done it all before in older Macs, be aware. In previous versions, OS X took one partition. Now it actually takes three logical partitions for boot, root and recovery. However, this detail is hidden in the OS X disk utility which only shows one partition, and in the background, re-partitions the root partition and moves the recovery partition along too. I did not realise this and instead of doing the above with the FAT partition, just made free space and let the Ubuntu installer automatically install Linux in it. It kept the first two partitions and gave me Linux root and swap, deleting the recovery partition - frak! Do not make the same mistake, always make sure you have chosen manual partitioning in the installer program - and then double check. If you know how to make OS X put back the OS X recovery partition, please let me know by emailing zeth at the domain name of this site.]
Linux Install
So now all the boring stuff is done, shut down the computer.
If you have the Ethernet dongle, then it is best to plug it in now to an Ethernet connection.
Stick the USB stick in to the USB port and boot to the USB stick by hold down alt (also known as the Option key - but it says Alt on the key!) when you turn it on.
If all goes well, it offers you the choice of Windows! Take that and it will boot the Linux installer from the USB stick.
Choose manual partitioning and delete the FAT partition you made earlier. As said above, don’t worry about swap right now. You can install a swap file later or just forget it. You have 8GB of RAM so hopefully swap will rarely be needed, and a solid state disk does not appreciate it anyway.
rEFIt
Your Linux install finishes, it reboots and ... nothing happens, OS X boots as before without any choice of Linux!
Now you have to install a boot menu. I installed rEFIt as I have done in the past and it worked fine. Then I read that there is the newer rEFInd. I got rid of rEFIt and installed rEFInd and it didn’t seem to work and it was getting boring so I swapped back to rEFIt. Your mileage may vary.
Anyway, now you have three choices on boot: Mac OS X, Linux or some weird emergency prompt.
Choose Linux and Grub boots “in a galaxy far far away”. Yes it is very very small!
The desktop of the Lilliputs
So there has not been a major or minor Ubuntu release since this laptop came out, and unlike some other friendly manufacturers, Apple do not make sure their hardware works with Linux before release (or in fact ever).
However, for now, there is no getting around that this is a very high resolution screen. You have a Linux desktop, but unlike any you have seen before.
There are two ways to work around this high resolution. One is to reduce the resolution in the monitor settings to a lower level, i and it didn’t seem to work and it was getting boring so I swapped back to rEFIt. Your mileage may vary.
The second approach is to fiddle with the settings of the desktop environment to increase the font size and the size of the title bars and menus etc.
I went through all the Lubuntu Preferences menus changing the default font size from 11 to 20. So now I can at least read everything easily. Some of the icons and things are very undersized but I personally hate any visual evidence of the Operating System anyway. I prefer my whole screen to only show my running application, everything else goes away until I call for it. Most of the stock Lubuntu apps (which are mostly GNOME ones) handle this quite well. So far, the only non-bundled app I have got around to installing is Emacs which copes perfectly.
Hardware support
So one of the attractions of this 13-inch model is that it has an Intel graphics card. My old Macbook Pro one had an Nvidia card which needed some proprietary blob and used up the battery much faster than Mac OS X would. The idea was that it would fallback to another chip when on battery, but that feature was not supported when I first installed Linux to it and never got around to looking into it again.
I am not a hardcore gamer, so I always prefer an Intel graphics card over the fiddly proprietary ones. They have a long battery life and tend to just work.
I also prefer a Linux wifi chip but sadly this has some brand new Broadcom chip. So you have to install the wifi driver for it. This is obviously easier if you have the Ethernet dongle we talked about above, if not you will need to download it to a USB stick or something to get it onto the laptop.
Installing the wifi drivers is another few commands. It is explained some way down this page and in this page. Hopefully it will be packaged in the future distro releases.
To get the sound card to work correctly, I needed to open the ALSA config file:
/etc/modprobe.d/alsa-base.conf
And then I added the following line to the bottom of it:
options snd-hda-intel model=mbp101
Other things
That is it really. Only remaining jobs are to remap a key to be middle click and maybe reduce the sensitivity of the trackpad. These are issues of personal taste so I will leave them for now.
This post is a bit rough but I thought it was worth getting it online as soon as possible in case it helps someone.
After installing the Lubuntu flavour of Ubuntu on most of my machines, I then had to remember how to setup the printer. This is a ‘note to self’ post, hopefully it might be useful to other people.
I don’t print a lot. It it easy and cheap to order family photos online or print them at the local photo shop. But when I do want to print (e.g. boarding pass), I want it to work.
That is why I hate inkjet printers, they are so unreliable and fragile, and the cartridges run out very quickly. So a few years ago I bought a laserjet. They cost a little more but actually work.
I did not want a scanner attached to the top. Scanning is much easier with a separate scanner that you can manipulate into different positions.
I wanted something with only a black cartridge and to be as simple as possible. The extra buttons and features are just gimmicks that nobody really wants (and probably are hard to get going on Linux anyway). I didn’t really care about having wifi or ethernet on the printer since it was expensive back then and, as long as the computer that the usb printer it is plugged into is turned on, Linux computers share usb printers very easily.

So I bought the Samsung ML-1915 which fitted the bill and love it. Everytime I see a friend or relative struggling with an inkjet I think fondly of my laserjet :) It once got completely covered in building dirt but cleaned up very well. It is has been a loyal piece of kit.
The world moves on and it has been replaced by more modern and cheaper printers like the Samsung ML-2165. It does not look quite so cool in white but it is half of the price so who cares.

Anyway my printer, like a lot of the Samsung printers, uses the Samsung Unified Linux Driver which for unknown reasons does not seem to be in Ubuntu by default, but it is pretty easy to install it.
Surprisingly enough, the Linux driver did come on a CD that came with the printer but it is easier to use the third party repository maintained at the bchemnet.com website.
Firstly you need to edit the sources list to add a repository, so open the file in your favourite editor:
sudo nano /etc/apt/sources.list
Now add the following line:
deb http://www.bchemnet.com/suldr/ debian extra
Then we need to add the key for that repository:
wget -O - http://www.bchemnet.com/suldr/suldr.gpg | sudo apt-key add -
Then we need to update the list of packages available:
sudo apt-get update
Now we can finally install the driver:
sudo apt-get install samsungmfp-driver
It would be much easier if that package was in the standard repositories but there you go. Now you can just add the printer using the normal graphical tool in your system.
In Ubuntu, this is under “System Settings” then “Printing”. In Lubuntu, this is under “System Tools” then “Printers”. Or you can just put system-config-printer into the terminal.
]]>The Guardian is ringing the death knell on the netbook. I would tell the story a little differently, so I will.

In the beginning was the $100 laptop dream
Before 2005, there were not many small factor laptops. I had the smallest Thinkpad, which was merely a smaller version of any other Thinkpad, which had a high end processor and lots of RAM, and it cost quite a bit back then. $1000-2000 dollars was the typical price for a laptop, and due to economies of scale, the then standard 15 inch screen laptop was always the cheapest model, smaller and larger sizes were a bit more expensive.
In 2005, the OLPC (One Laptop Per Child) X1 was announced - a $100 laptop aimed at children, with a special low power processor from AMD, running a version of Fedora Linux, with suitable proportions for a children. The X1 included a video camera, touch screen, sd card slot and wifi; features that were considered high end in 2005.

The dominant computer companies had a collective nervous breakdown at the mere concept of it. While everyone appreciated the new and noble idea of OLPC, the existing market leaders were extremely hostile to it. Microsoft lobbied departments of education around the world, telling them that if they bought their children non-Microsoft devices then their future careers would be ruined forever, etc, etc.
Meanwhile Intel did something a little more positive in that it dusted off its shoes and worked with hardware manufacturers to get Intel powered devices to the market. The first was ASUS with its educational “Classmate PC”, and the consumer oriented counterpart the Eee PC.
Until this point, the trend of processor manufacturing was towards increasingly more powerful (and hungrier) processors. Intel didn’t even have a suitably efficient chip so it under clocked its lowest laptop processor from 900 MHz to 630 MHz. Later it would get its act together with its Atom chip, but a little late as ARM based chips had already gotten most of the market.
Nobody cared about the Classmate PC, but despite the stupid name, the Eee PC was a big hit. Despite the bizarre 1980s style border around the screen, the early 701 series models were great, they had solid state drives and cost around £200. They were also light enough to use while holding them up, unlike the bulky laptops a lot of people still had back then.

It might not sound it like it now, but in 2007 it seemed really cool that with a netbook, you did not bother with a specialised multi-pocket laptop bag, it was not a chore to throw it into your backpack and keep it with you at all times. If the worst came to the worst and it was lost or stolen, £200 is rather less of a shock than £1000-2000.
Meanwhile, the OLPC project has had some solid achievements, and 2.5 million kids using the XO laptops, but the initial excitement and the wide coalition of support faded out, and it has not yet managed to overcome the political and monopolistic obstacles to a global roll out. It also never got into the required production volumes to be exactly $100 per unit. If you are a department of education, especially a developing world country, $100 per child is already a lot, a $200 dollar laptop for each child proved to be out of the question. [They always seem to have enough money for military jets and nuclear programmes though!].
This is is a shame because the Sugar interface is a fantastic learning tool for children. Maybe its time is still to come. They are trying to pull everyone back together for the launch of the new iteration, the XO-4, sometime this year.
Netbooks and dodgy Linux pre-installs
A lot of other manufacturers brought out ‘netbooks’, we were given an Acer Aspire One by a relative, and some of them, including the Eee PC, came with Linux. What I have never understood about netbooks, is that they always came with an unknown and slightly crap form of Linux, with almost no decent applications on them.
In the wider desktop and laptop markets, Linux users tend to install Linux distributions as an after-market upgrade, sidelining or wiping out completely the redundant copy of Windows install that came pre-installed with the computer. It is an extremely competitive market; at the time of writing this article, the DistroWatch website lists 314 currently available Linux distributions.
A lot of these are hobbyist or specialist efforts, but out of this whirlwind come a handful of really big ones, that the majority of Linux users actually have installed. Ignoring distributions aimed at technically proficient users such as Gentoo, Arch, and Slackware, the big ones include Ubuntu, Fedora, SuSE, Debian, Mandriva and Mint.
These are all free, so why didn’t the netbook manufactures install these? They have a proven track record of usability and popularity and existing teams working on improving them. If Ubuntu alone has 20 million users already, then why not sell what these people want? The highly innovative world of Linux, with things constantly forking and splitting, probably does not make it easy for manufacturers, but the big brands like Fedora and Ubuntu are pretty stable participants. Fedora’s backer Redhat had its famous IPO in 1999 and is a S&P 500 company.
I have no idea why laptop manufacturers and the big Linux distributions have not done a better job at working together. Of course, there is obviously a massive obstacle in the entrenched Windows monopoly and the marketing budget that Windows gets from its monopoly profits.
Small companies who pre-install Linux on computers as a boutique service for time-poor Linux users are not readily assisted by the manufacturers of the laptops. Dell had a half-effort at selling Ubuntu laptops, but not in the UK, maybe that will increase. Canonical now seems to be having some new efforts on working with manufacturers with regard to tablets so we will see how that pans out.
In the mean time, what people commonly call “Real Linux” distributions have been completely overtaken by the rise of Android, as we will come to shortly.
2007-2010 - The short reign of the netbook
Despite some promising signs, the netbook boom ended pretty quickly. I agree with the Guardian article on that to a certain extent.
As the Guardian points out, the first major blow was specification creep. The computer hardware industry’s habits would not die easily, and they soon watered down the concept. Instead of a small fast portable computer with a web browser, simple fast applications, no moving parts, and costing £200, they soon reverted to type: to make Windows and its accompanying bloatware perform decently required better hardware, regular hard drives replaced solid state storage, whirring fans came back, battery run times collapsed, and they soon crept back up to £300-400.

Going further than the Guardian article, I would add here that the second and more important blow was a lack of software innovation. Microsoft worked hard to make sure Windows got the lion’s share of pre-installs, but it did not attempt to do anything innovative in the netbook space. It provided either the dated Windows XP (launched in 2001), or a crippled version of its later systems. It did not attempt to create software relevant to a low powered portable device. So the majority of netbooks were sold with software not particularly designed for it.
The third and fatal blow was the launch of the iPad in 2010, and then the arrival of even better Android tablets. A lot of computer users are passive information consumers, and short form and asynchronous interactions of the social networking boom are not inhibited by the lack of a physical keyboard. Unlike netbooks, tablets managed to free themselves from the Windows baggage and have specially tailed operating systems.
Tablets and phones fatally bisect the netbook market; occasional and light users can just use tablets and phones, professionals can afford the $1000 small factor laptops, ‘Ultrabooks™’ as Intel calls them.
However, I think the fact that netbooks were sold with unsuitable Windows operating systems was the biggest factor. I think with the right tailored software, netbooks can be useful tools.
The rise of Android and Chrome
While the “Real Linux” distributions were mostly ignored by the manufacturers. In an act of genius that we almost have come to expect from Google as a matter of routine, it got the concept of commodity computing and used it as a way to increase usage of its own services. Android and Chrome are technically Linux, but all the common applications are replaced by Google’s own offerings, and whatever crap the manufacturer adds on.
Long time Linux users were initially not impressed they could not easily use their existing applications and the fact that it launched with a Java only development environment alienated a lot of C and Python developers on the Linux platform who felt lobotomised by it. Over the last five years, the Linux community has mostly come to terms with Android.

Android is the most successful distribution in the history of open source software. Don’t get me wrong, I like it a lot, I have Android devices and I love them in their own way, but it is not want I really want for my primary computing device. This would take another whole article to explain but Android is Linux but with all the joie de vivre, the joy and enthusiasm, sucked out of it. Also, I still it is relatively early days in open source software, the big game changing Linux device has not been invented yet.

Here is where I have to really depart from the Guardian article, they claim that no netbooks are being released. Well I think that must be a pretty narrow definition of a netbook.
Chromebooks, netbooks with Google stuff preinstalled rather than Microsoft’s, are the second incarnation of netbooks. Because Chromebooks use a special BIOS and bootloader, it is currently a bit of a faff installing your own Linux distribution, but it is possible and hopefully it will get easier over time if the distros find some easier way of installing on Chromebooks.
So from the perspective of a Linux user, despite the initial faff, Ubuntu on an Acer Chromebook is little different than running Ubuntu on an Acer Aspire. For me Chromebooks are still netbooks.
Netbooks will not die
For me the netbook format is still relevant and will not die (yet at least).
Tablets are like small babies, you have to hold them all the time, I haven’t mastered the art of propping the iPad up. Even bespoke stands are never around the moment you want to put the tablet down. Giving a presentation from a tablet or a phone not only requires being very organised - it is hard to make last minute changes from a tablet, it is also quite expensive to get a VGA connector for them (and you have to not lose it).

I know it is not trendy, but sometimes you just want to use physical keys. I do have a very nice bluetooth keyboard for my Android powered Samsung S3, but Emacs does not work very well on it, it is not ported very well and Android’s own features try to take over. Although I will hopefully get over some of these problems over time.

At the moment I am very lucky to have a high end laptop due to the nature of my job. However in general, I am a desktop type of guy. I like buying the components and screwing them together. I like being able to stick more RAM in later when it becomes cheaper. I like being able to scavenge for spare parts and turning three broken machines into two working ones. I like two full sized monitors.

I hate it when expensive laptops break, in general these are not fixable at home and have to be sent away, which can be as expensive as a netbook, but is also inconvenient being without it for several weeks.
For me a netbook is a very nice complement to the desktop/home media server type setup. It works enough offline, and with a good connection I can use the full power of my home desktop remotely. If it breaks it is less of a problem, being £200 to replace.
Chromebooks
Lets have a look at some Chromebooks.

The cheapest current Chromebook seems to be the Acer C7 Chromebook which at $200 and £200 is a pretty unfair currency conversion, it certainly one to buy while in the US, or perhaps have posted from a US seller if you are not in a hurry. I like the fact it has VGA (for projectors) and HDMI (for TVs) and still has an ethernet port (for plugging into a wired network) which is rare this days. It is not lacking in power with an over-generous 2GB of RAM. It has a massive 320GB old fashioned hard drive, which you will either love (lots of storage and less fear of disk corruption) or hate (it is a moving part which can make noise and potentially fail). I personally would prefer a small solid state drive.
If you get through the Chromebook bootloader hassle and successfully get Linux installed, since it has an Intel processor and graphics, it should work pretty well. Intel graphics is a plus since Intel stuff normally works automatically without the need for a proprietary driver (but then I am not a gamer, Linux gamer types always seem to get Nvidia graphics). It does not say what the wifi chip is, if it is Intel too then all the better.

More expensive, but at least with a sane UK price, at $325 or £230 is the Samsung Chromebook. It also has 2GB of RAM but it is slim and fanless with a 16GB solid state drive and bluetooth.
So in many ways it is a better machine than the Acer but it is ARM, which is the trendy thing but there is no support for hardware accelerated graphics at the moment for Linux on this ARM chip and some proprietary software might not work either if it does not have an ARM binary, if you rely on Skype or Flash or something, you might want to check if these work on ARM. However, Michael Larabel of Phoronix has reported good things about it.
Both seem nice but neither are the perfect netbook.
Less is more
Fundamentally, I think these are still too high expensive and in that sense, netbooks have not really begun yet.

Of course when compiling software or doing video editing or whatever, one still wants the best computer possible. However, If I was designing a netbook, I would accept that in 2013, you are likely to have many computing devices - phones, tablets, smart TVs, desktops and games consoles and so on. I would explicitly make it good at being a cheap portable laptop you sling in your backpack.
The ‘Zethbook’ would be a small factor laptop with modest (32GB or 64GB) solid state drive and preferably no fans or other moving parts, with no more than 1.0 GHz processor, and no more than 1GB of RAM, preferably with Intel graphics or some other Linux supported chipset.
The Zethbook could then be incrementally improved in other ways that do not involve unnecessary bloating up the cost and power usage, as battery technology improves but the processor stays the same, why not 100 hours of usage? Why not 1000 hours? Make it sandproof for the beach, make it waterproof so you spill a whole glass of soda over it or use it in the shower. Make the keyboard better, improve the screen resolution, make it more user modifiable. Improve the shock resistance so it can cope with being accidentally dropped open with the screen hitting the floor first, let it be bike proof and fall off the handlebars at 20 mph and hit the road without damage. Let it fall out of a car window at 60 mph.

It is great that computers get more powerful every year, but I think it is a bit too one-sided. The international Space Station runs on the 386 processor which was brought out in 1985. The Linux kernel and GNU GCC compiler are now starting to remove support for it now, but the 386 is still (in theory) usable with Linux for a while longer. Going forward in time, with an efficient choice of operating system, 95% of things can be done on a Pentium 4 computer from 2000. It is just lazy programming that requires bloated systems all the time.

Sadly you won’t see the Zethbook any time soon. Boards aside, the OpenPandora (warning: linked web page has sound) is the nicest complete Linux device I have seen so far, it is a handheld game console costing over $500. It is not that easy to get the price down without being made by the biggest manufacturers like Asus, Acer or Samsung etc.

The Raspberry Pi Model B is perfectly usable at 512 MB and 700 Mhz (twice as powerful as the original version of the OLPC XO). The Raspberry Pi Model B is $35. Granted it does not have a keyboard (cheap) or a screen (expensive) or wifi, but we can still imagine a portable device for $100, which of course, is the OLPC dream that started the netbook story. I am quite interested in those who are putting the Raspberry Pi in home made mobile forms and may follow that up in a future post.
Let me know your thoughts on netbooks. Do you love or hate the netbook. Will you miss its passing if it does die out? Do you like or hate the idea of Chromebooks?
Ever thought about building your own CCTV system? All you need is free and open source software Zoneminder, a free Linux distribution such as Ubuntu, Lubuntu or Debian, an old PC and a camera.
What is Zoneminder?
Zoneminder is an open source application used for CCTV and other security and surveillance applications. You can use it to monitor your home or work property or to monitor your pets while you are out, whatever you can imagine really (look at the screenshots on the Zoneminder homepage for more ideas).
The implementation is basically a Perl/PHP web app using Apache and MySQL (LAMP as we call it in the trade). If you have ever set up a website or blog or something then you will understand it instantly. It is a nice concept as using shared nothing web application and system administration principles it can scale up indefinitely to very large commercial uses.
If you are the kind of person who already has a home wifi or wired network and a home server or desktop on all the time, then Zoneminder will fit in great, as the only extra electricity you will be using will be the camera (or cameras) themselves.
Zoneminder is really flexible and configurable, which is fantastic but also means that you do have to configure it for your own needs. If you have quite a minimalist IT setup at home with no machines running most of the time (e.g. just a iPad in your Thames-side studio apartment), then using Zoneminder at home might be overkill, as you can probably buy a pre-made embedded home CCTV system that runs off a single plug and does not require configuration.
Zoneminder stores the recorded video as single frame images in a simple data layout on your filesystem and the web application allows you to configure it and view the cameras in real time and view recorded footage. The metadata is stored in the MySQL database.
What kind of camera do I need?
It seems you can use anything. If you have a simple USB webcam lying around at home, that is all you need to get started. If then you like Zoneminder you can then get a posher camera later if you want.
There different types of cameras depending on how serious you are. The more serious people put a card in their computer (such as the Hauppauge Impact VCB/PCI Composite AV Input card ) and use real high definition video cameras.
I personally use a ‘netcam’ (I have the model called TRENDnet SecurView Wireless N Internet Camera if you want to be precise) which is basically a webcam with a built in wireless card (and or ethernet socket). So you can put the camera anywhere you can power it and it will log onto your wireless network like any other device. You don’t have to run AV cables back to your computer.
[The same advice that I always give concerning routers and other network devices applies here: if you buy such a netcam, check its website for any firmware updates, especially security updates, before you add the device to your network. These things are little network connected computers after all, containing a proprietary operating system. This system may have been written by a guy with a masters in network security from MIT, or it could have been written by a subcontractor earning £1 per hour in who knows where. The problem with all proprietary software is that there is no public peer review (unlike with open source software). So check the vendor for security updates.]
If a burglar manages to get in and picks up the netcam, there are no wires to follow back and so no clue as to where the images go. One can also use backup software or write a few bash scripts to copy images to a remote server or the cloud if you are in a high crime area. If you have a really good internet connection at both ends, you can put netcams in your relatives’ houses and allow your Zoneminder server to grab the images off.
What kind of server do I need?
By ‘server’ in the article, I just mean the computer that will have Zoneminder installed, as opposed to any other computers, tablets, phones or even TVs you might use to operate the system on a day to day basis.
I suppose (in theory) you could use any operating system that can run Perl, Apache and Mysql. However, the assumption from here is that you will be using a Linux distribution, because Windows and OS X are, to put it bluntly, completely crap in this server role and a massive hassle to work with. If you have a Linux Desktop already at home, then that will probably work fine.
In my experience, the server does not need to particularly powerful for a simple home setup. I am using a low-powered PC from 2006 which runs Zoneminder and lots of other apps quite nicely.
You don’t have to have a graphical system, you can use something like Ubuntu Server if you want. However, you will need some computer or phone with a web browser to control Zoneminder and view the saved images/video, this does not have to be a Linux computer (toy operating systems work fine as clients).
Source vs Packages
A couple of years ago I installed Zoneminder on Ubuntu 11.04 by downloading the source. Now over Christmas I had a spare 20 mins and re-installed the OS. I like backing up and reinstalling occasionally as it gives a nice clean system. This time I went for Ubuntu 12.10 in the Lubuntu flavour (I will talk about that in the future). Then I had to put all the data and programs back on.
Last time I installed Zoneminder from source, this time I thought I would try the Ubuntu packages. This guide should work for any Ubuntu or Debian type system, but your mileage may vary.
Lets get started.
Firstly, we need to install the zoneminder package, you can do this in the graphical “software centre” or you can just open a terminal and use this command:
sudo apt-get install zoneminder
On a fresh system without Mysql, it will ask you to set a Mysql root password. Next it configures the nullmailer mail relay, I just accepted the default answers. Then it stops returns control of the shell.
Apache settings
Now we need to let Apache know what is going on. If you are already using Apache to show websites on this system, you can integrate Zoneminder in a way that does not clash with your other sites.
However, on a fresh system, you can do this:
sudo ln -s /etc/zm/apache.conf /etc/apache2/conf.d/zoneminder.conf
sudo /etc/init.d/apache2 reload
Now when you go in your web browser to http://localhost/zm/ you can now see the console.
If you have installed Zoneminder to a non-graphical server distribution, then obviously use the IP address or domain name instead of localhost when you access Zoneminder from your external computer or phone or whatever.
Camera Setup
When you click on Add New Monitor, you get a web form that looks like this:
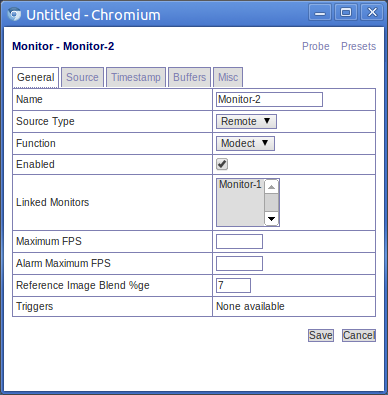
The most important field here is “source type”, the setting chosen affects the options available in the source tab (see below). Since I am using a netcam, I set it to remote.
Another important field is ‘Function’. Modect is short for ‘motion detect’, it records when there is motion, other options include constantly recording and just monitoring without recording.
Now we come onto the source tab, as shown below:
This window allows you to define the hostname of your camera. So for a netcam we give it the host name of the camera, which in a home setup will probably be a private ip address (e.g. 192.168.x.x). Look up your camera on the Supported hardware section of the Zoneminder wiki to find what settings you need to add here.
Log driven configuration
You can read the Zoneminder ‘system log’ by clicking on a link unsurprisingly called ‘log’ (as shown in the main console screenshot above). This gives as a log viewer, as shown below:
The way I configure Zoneminder is by reading the activity log and keep changing configuration until it stops moaning.
So I started with this error:
Can't open memory map file /dev/shm/zm.mmap.1, probably not enough space free: Permission denied
This due to the default settings of Ubuntu (or Lubuntu in my case). There is a kernel setting called shmmax which determines the maximum size of a shared memory segment i.e. the total amount of RAM that can be used when Zoneminder is grabbing images from the video driver.
[You may vaguely remember doing this before because some ‘enterprise’ (i.e. bloated) databases and other business software often requires this too.]
So on my fresh install, shmmax was set to 32MB by default and it needed to be more than 96MB, so I increased it to 128MB to be sure.
How much you need depends on how posh your camera is. The higher resolution the camera, the more RAM Zoneminder will need to use.
A quick hack way is to just override the number in /proc, obviously this only works on the live system, when you reboot the setting is gone. However, it is a quick way to play about with the setting:
sudo su
echo 536870912 >/proc/sys/kernel/shmmax
exit
You can work the setting by trial and error but you can also just to look in the Zonemaster wiki, or to google it, as it is likely that someone else is already using Zonemaster with the same model of camera you have.
I restarted zonemaster:
sudo /etc/init.d/zonemaster restart
And it solved the problem. So because I then knew it worked, (as advised by Zonemaster wiki), I made a config file to do this on boot:
sudo su
echo kernel.shmmax = 536870912 >/etc/sysctl.d/60-kernel-shm.conf
sysctl -p
exit
Next up in the log was the error:
waiting for capture daemon
This is fixed by adding the web server user to the video group:
sudo adduser www-data video
(Why isn’t this sorted out by the .deb package? And why is it not given its own user?)
Just keep attacking the log errors until it is all happy really.
Configuring Image Location
By default the images are bunged into: /usr/share/zoneminder/events which is a symbolic link to /var/cache/zoneminder/events/1/
In theory, to change this you need to change the setting ZM_DIR_EVENTS which is the first setting under ‘Options’ then ‘Paths’. Use an absolute path and make sure the destination has the correct permissions.
In reality, I never had much luck changing this. When it tries to read the events back, it seems to be somehow hardcoded to the old location which is then appends with this location. If anyone has the answer to this let me know.
So instead I have had more luck just ignoring this configuration option and instead myself replacing the symbolic link /usr/share/zoneminder/events with my own:
sudo rm /usr/share/zoneminder/events
ln -s my_better_location /usr/share/zoneminder/events
By default there is no lockdown on the web interface, so if the machine is web accessible, you will want to change that (options > OPT_USE_AUTH). When you first turn on authentication, the username is admin and password is admin. You will probably want to change that too! (Options > Users - only appears when authentication is turned on).
There are lots of other things you can configure like the sensitivity of the motion detection and which regions of the image to watch and which to ignore it etc. However, we have covered everything specific to using Zoneminder on an Ubuntu/Debian system using the .deb packages. The Zoneminder wiki is very useful and comprehensive so dig around there to find out more.
Zoneminder in action
Now if you have read this far you deserve to have some silly pictures.
Having a CCTV camera at the front of your house educates you a lot about what happens in your local community. I have learned all sorts of things from watching back footage at random. Most of the cool snaps I probably cannot post online for legal and taste reasons.
The first revelation is that a large amount of people look through your windows. Here is a fairly tame and blurry one.

I have had people come right up to the camera and look through the windows. One person even wrote down details in a pad.
Where does the box load of paper spam come from? Well Zoneminder will tell you. Here is a guy promoting a pizza company:

Here is a free ‘newspaper’ full of ads:

Fortunately, we still have real postmen. But they seem to be far more informally dressed than Postman Pat:

I think he was a special temp over Christmas. Sadly they all seem to have these granny trolleys now instead of the cool Pashley bicycles they used to have.
Fortunately, the dustmen come and take all this rubbish away, even in heavy rain:

Over to you
So setting up Zoneminder takes a little fiddling but it is good fun and reassuring to have the ability to look back in time at what was happening in front of your house in the past. If you have a go or have tried Zoneminder before, please let everyone know how you got on and how I could improve this guide. Bonus points for silly pictures.
When I started this site in 2005, I said that my blog was:
“about taking control of your own technology, it looks at our experiences of computing; especially computing using GNU/Linux, often using the command line and other textual means, but also other issues such as ethics, best practices and whatever is cool now.”
In 2007, in answer to a question, I provided this further description:
“The broader meaning is someone who is willing to take the extra time and effort to think through and take control of all the technology that is entering into our daily lives; to make sure that our freedoms, hard-fought for on the battle field, protest rally and ballot box, are not quietly surrendered in the digital age, but instead freedom must be at the very foundation of technology itself.”
About a year ago (December 2011), I decided to take some time off writing here. I thought that if I stopped writing blog posts and stopped writing mailing list posts and stopped Tweeting it would give me more time and energy to make progress in other areas of my life.
I was wrong.
By not engaging with the interests and interested communities that got me where I am philosophically and technically, my passion started to fade and I lost those key insights that only come from interacting with others in the field.
So I have decided to try to restart writing. All previous entries from 2005 to 2011 are now archived, and I have a clean new chapter to begin.
Bear with me as I build up confidence again as a writer. The biggest difficulty I have is writing to a silent audience. It is difficult to know which topics to address if I do not know the audience’s interests. So please do give me your comments and ideas. There is a comment box available below and my twitter name is zeth0.
]]>
4. Social Networks Suck
To bridge this easy to read/hard to write gap, the social networks jumped in. These are easy for people to quickly post their cat photos and show off.
The concept ‘net neutrality’ describes how the WWW is (supposed to be) broadly content indifferent, it is just a pipe to push information through. Mesh networks described above take this concept even further.
Social networks are a downgrade from WWW, in that now content is inside silos that are centrally controlled by a private company with no requirement to enforce freedom of speech.
James Delingpole wrote an article about his problems being a centrist/conservative journalist and media personality using West Coast controlled social networks to promote his work:
Sounds like a lot of work.
James Delingpole has a nice podcast, if his content is good enough, his fans will share it, it doesn’t matter if he is on Facebook himself.
I am probably too old for Milo, but I notice that every time Milo does something, it still appears on Twitter, despite Milo being banned, because his limitless undergraduate fans share it.
Many years ago, I used to play MUD games and even wrote one once. One famous MUD had inside its introductory help file, something like “don’t base your life on a game you don’t control and can be banned from.”
Kind of why I stopped playing MUDs, when you find a MUD that doesn’t ban you, they tend to put you in charge. You cannot really play in peace as a casual player, even if you try to, someone will redesign the world half way through and negate all the time you put into building a character.
Another way of putting it is James is like an Ambassador to the USSR.
An Ambassador to a hostile country should always know they are on borrowed time. At any time the host country can revoke the credentials and force a replacement.
Maybe the Ambassador did something wrong, maybe not, maybe they were just too effective or were not able to be turned.
The Ambassador shouldn’t go native and base his life on being able to stay.
To take a different analogy, Western bishops used diplomatic charm to try to protect Russian Christians from being killed by the Atheist USSR.
No doubt useful work but appeasement and trying to fix the USSR wasn’t what won the cold war.
It was consumer goods, making the free world demonstrably better for ordinary people, this is what brought down the USSR.
Facebook is a totalitarian state, some people thrive there but generally, it is better to get out while you can.
The semi-free world is the WWW, the really free world is the Mesh, the darknet, peer-to-peer networks and Tor.
If possible, I want to build up the free world but it will happen anyway if it is meant to. Technology may or not be imbibed with a spirit, but it seems to have an inevitability about it.